


Si eres de los que quieren tener todos los datos disponibles para desarrollar tu estrategia de SEO, SEM o contenidos, extraer las tendencias de Google Trends a través de Pytrends te abrirá un abanico de posibilidades.
¿Qué es Google Trends?
Google Trends es un servicio totalmente gratuito donde puedes analizar el interés de una palabra o consulta concreta a lo largo de un periodo de tiempo específico, ya sea de forma global o geolocalizada.
Esta herramienta presenta muestras de los datos solicitados a partir del año 2004 hasta la actualidad, aunque empezó a funcionar unos años después, en 2006. Si quieres más información sobre el origen y los datos que muestra, la tienes aquí.
¿Qué es Pytrends?
Pytrends es una API no oficial de Google Trends para Python. Nos permite extraer datos de todo tipo relacionados con el interés de los usuarios por un tema o una consulta concreta.
Al igual que en la propia herramienta de Google, podemos extraer información a nivel mundial o geolocalizada, en temporalidades específicas e incluso en base a una categorización propia de las consultas.
Instalación
Para empezar, debemos instalar pytrends en nuestro cuaderno de Google Colab e importar las librerías que necesitamos.
1. #Instalamos pytrends 2. !pip install pytrends 3. 4. #Importamos las librerías que vamos a utilizar 5. import pandas as pd 6. from pytrends.request import TrendReq 7. pytrend = TrendReq()
Al ejecutar el código anterior veremos como se instalan diferentes paquetes y librerías.
Extraer datos con Pytrends
Para poder seguir avanzando y que podamos extraer todos los datos que queramos de Google Trends, debemos tener muy en cuenta cuáles serían los que podemos denominar como métodos API.
Básicamente son parámetros que utilizamos para definir lo que queremos hacer con la solicitud que realizamos y una respuesta a la misma.
Estos nos permiten conocer prácticamente por completo lo que se puede hacer con Pytrends y los datos que podemos llegar a obtener.
- Interest Over Time
- Historical Hourly Interest
- Interest By Region
- Related Topics
- Related Queries
- Trending Searches
- Top Charts
- Suggestions
Analizaremos más adelante que podemos hacer con cada uno y veremos el resultado a través de nuestro cuaderno en Google Colab.
Por otro lado, todos los anteriores utilizan determinados parámetros que son prácticamente comunes entre todos ellos. Estos parámetros nos sirven para especificar y filtrar mucho más nuestra búsqueda.
Empezando con Pytrends
Para poder extraer datos de Google Trends con Python necesitamos varias líneas de código que incluyen los parámetros que antes comentamos.
Gran parte de esta información está disponible en la documentación de Pytrends, pero voy a intentar explicarlo de una forma sencilla:
1. #Conectamos con Google Trends y le pasamos unos parámetros base 2. pytrends = TrendReq(hl="es") 3. #Establecemos una variable lista que incluya la palabra o palabras que queremos analizar 4. lista_palabras = ["Consulta que vamos a realizar"] 5. #Pasamos todos los parámetros que queremos a la solicitud (filtrado) 6. pytrends.build_payload(lista_palabras, cat=0, timeframe="today 6-m", geo="ES")
Como ves, se compone de 3 líneas de código que, aunque no sepas nada de Python podrás interpretar fácilmente.
Función TrendReq
La función TrendReq() permite hacer un primer filtrado de los datos que vamos a solicitar. En este caso, solo indicamos el idioma para acceder a Google Trends, pero hay muchos más parámetros que se pueden utilizar:
1. pytrends = TrendReq(hl='en-US', tz=360, timeout=(10,25), proxies=['https://34.203.233.13:80',], retries=2, backoff_factor=0.1, requests_args={'verify':False})
- hl: Idioma con el que nos conectaremos a Google Trends. Como ves en el anterior ejemplo, también se pueden usar diferentes combinaciones de idiomas en función de la solicitud que realices.
- tz: La zona horaria. En este caso funciona a través de CST.
- Timeout: Establecemos un tiempo de espera para la solicitud en caso de que haya problemas con el servidor.
- Proxies: En caso de que se hagan muchas solicitudes se pueden usar proxies para evitar bloqueos por parte de Google. Se compone de proxie + puerto.
- Retries: Número de intentos para conectar con el servidor.
- Backoff_factor: Se crea una demora entre intentos.
- Request_args: Permite pasarle otro tipo de parámetros. Por ejemplo, para evitar errores SSL en la solicitud.
En la segunda línea establecemos una variable lista, donde podremos poner una o varias palabras para analizar.
Construyendo la solicitud
La tercera línea se compone de parámetros mucho más específicos para realizar la solicitud. Básicamente, le decimos que elementos debe tener en cuenta a la hora de solicitar la información.
1. pytrends.build_payload(lista_palabras, cat=0, timeframe="today 6-m", geo="ES")
- Lista_palabras: Tendrá en cuenta la lista de palabras que hemos asociado a la variable anterior. Es obligatorio pasarle este parámetro.
- Cat: Esto creo que es algo realmente interesante, ya que Google Trends hace una clasificación de sus consultas en función de una serie de categorías específicas o temáticas. Dichas categorías están referenciadas con unos números específicos. Más adelante veremos cómo podemos sacarle el máximo partido a este parámetro.
- Timeframe: Le indicamos la fecha desde la que queremos que extraiga los datos. En el caso del ejemplo, extraeríamos los datos de los últimos 12 meses, pero también podemos usar all para un histórico completo o fechas concretas.
- Geo: Geolocalizamos los resultados. Podemos utilizar abreviaturas como ES e incluso zonas más específicas.
- Otros parámetros menos utilizados: También se pueden utilizar parámetros como «grpop», que establece un filtrado en función de la búsqueda (Se puede usar news, images, etc) o «tz», para indicar la compensación horaria.
¿Qué podemos hacer con Pytrends?
Ahora viene lo mejor, donde podremos ver todo el potencial que tiene Pytrends y todos los datos que nos ofrece.
Dependiendo de cada proyecto, puede que interesen datos muy distintos, así que solo veremos como aplicar los que pueden ofrecer información muy relevante.
InterestOverTime
Con este método comprobamos el historial del interés a lo largo de un plazo determinado sobre una o varias consultas.
En este caso utilizaremos la consulta pfizer.
1. #Conectamos con Google Trends y le pasamos unos parámetros base 2. pytrends = TrendReq(hl="es") 3. 4. #Establecemos una variable lista que incluya la palabra o palabras que queremos analizar 5. lista_palabras = ["pfizer"] 6. 7. #Pasamos todos los parámetros que queremos a la solicitud (filtrado) 8. pytrends.build_payload(lista_palabras, cat=0, timeframe="today 12-m", geo="ES") 9. 10. #Ejecutamos pytrends.interest_over_time() pytrends.interest_over_time()
Resultado:
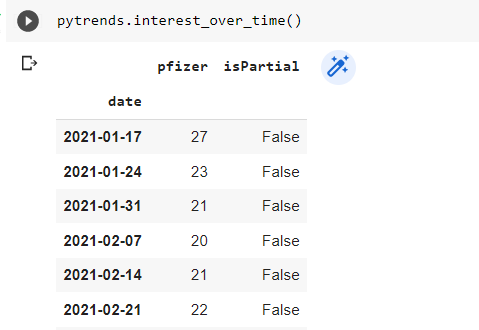
Como veis en la imagen, nos muestra una tabla con una puntuación establecida por Google Trends cada uno de esos días.
Lo mismo podemos replicarlo a varias consultas para poder comparar estos datos.
Para el ejemplo, utilizaremos los términos pfizer y moderna.
1. #Establecemos varias consultas dentro de la variable lista 2. lista_palabras = ["pfizer","moderna"] 3. 4. #Pasamos todos los parámetros que queremos a la solicitud (filtrado) 5. pytrends.build_payload(lista_palabras, cat=0, timeframe="today 12-m", geo="ES") 6. 7. #Ejecutamos pytrends.interest_over_time() 8. pytrends.interest_over_time()
Resultado:
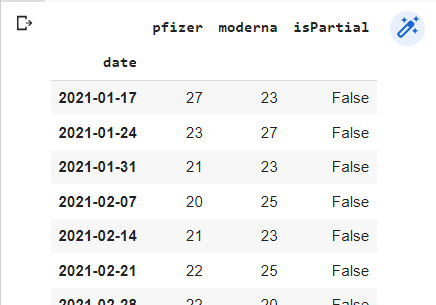
Estos datos podemos utilizarlos para entender la tendencia de una palabra clave durante un período de tiempo determinado o incluso comparar tendencias entre varias. Si estás trabajando con productos estacionales o quieres comparar el interés de marca entre tú y tus competidores, tendrás mucha información.
Podemos utilizar la librería de matplotlib para pasar estos datos a un gráfico y ver todo de forma mucho más visual.
1. pytrends.interest_over_time() 2. grafico = pytrends.interest_over_time() 3. grafico.plot(figsize=(12, 10), y=lista_palabras)
Resultado:
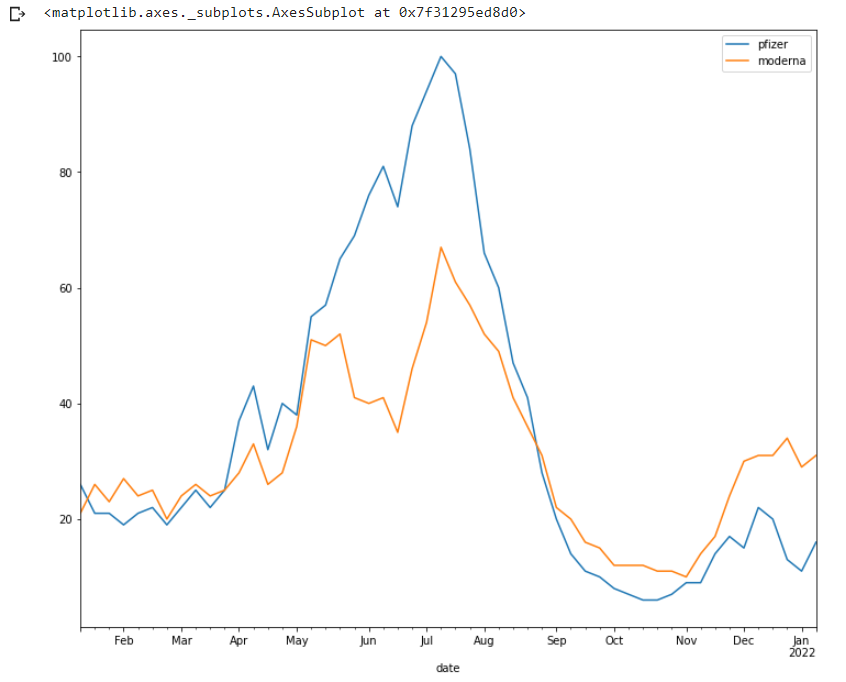
Interest By Region
Gracias a interest_by_region podemos conocer la tendencia de una o varias palabras en función de su zona geográfica.
1. pytrends.interest_by_region(resolution="COUNTRY")
Resultado:
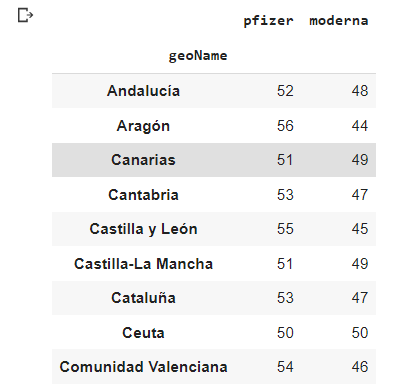
Si trabajas con proyectos de SEO local, esta opción puede venirte realmente bien para conocer tendencias de búsqueda entre comunidades o incluso para comparar la tendencia de un producto o marca en función del lugar.
Por otro lado, si trabajas con un proyecto muy enfocado a una región y quieres expandirlo al resto de España, con estos datos puedes ir comprobando el conocimiento de tu marca o producto en el resto del país.
Related Topics
Quizás esta sea una de las opciones con más potencial de Pytrends. Gracias a ella podemos descubrir los temas o topics más relacionados con una palabra o entidad específica.
Te recomiendo que solo utilices una palabra en esta solicitud para obtener unos datos más precisos y totalmente relacionados con la misma.
Al utilizar una sola palabra en el análisis podemos asignar una variable a nuestra salida y utilizar el método .get para pasarle la palabra de origen y especificar el formato de los datos que se extraen.
Gracias a Pytrends podemos obtener las entidades con un volumen creciente en la temporalidad especificada hasta el top de entidades más relevantes durante dicho periodo.
Para el ejemplo, utilizaremos la consulta cruceros.
Topics con volumen creciente durante el periodo establecido:
1. #Indicamos la consulta que queremos realizar
2. lista_palabras = ["cruceros"]
3.
4. #Pasamos todos los parámetros que queremos a la solicitud (filtrado)
5. pytrends.build_payload(lista_palabras, cat=0, timeframe="today 12-m", geo="ES")
6.
7. #Ejecutamos pytrends.related_topics()
8. pytrends.related_topics()
9.
10. #Indicamos que queremos los topics con un volumen creciente
11. #durante el período de tiempo establecido
12. analisis_tendencia = pytrends.related_topics()
13. analisis_tendencia.get("cruceros").get("rising")
Resultado:
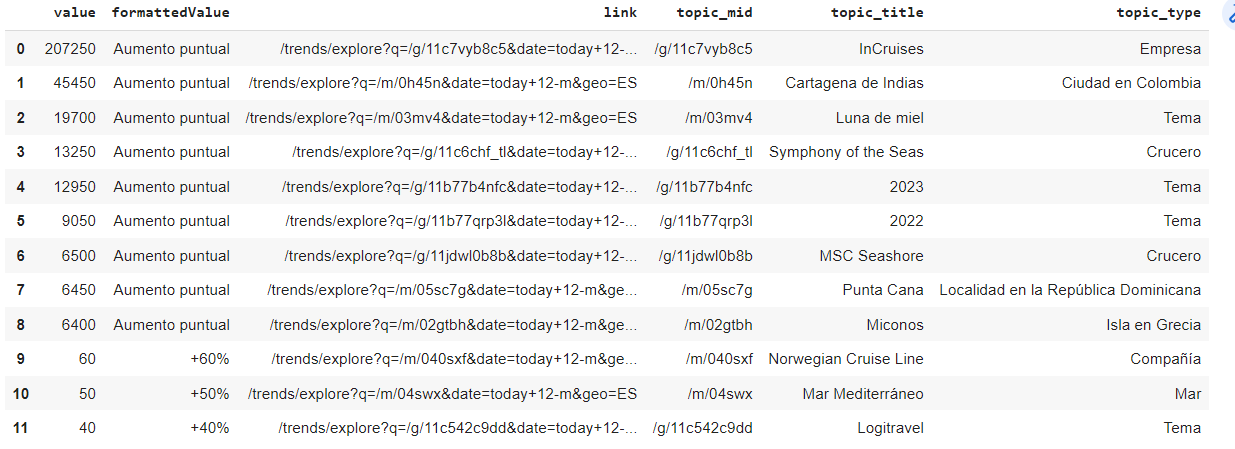
Top de topics durante el periodo establecido:
1. #Ejecutamos pytrends.related_topics()
2. pytrends.related_topics()
3.
4. #Indicamos que queremos el top de topics en ese periodo
5. analisis_tendencia = pytrends.related_topics()
6. analisis_tendencia.get("cruceros").get("top")
Resultado:
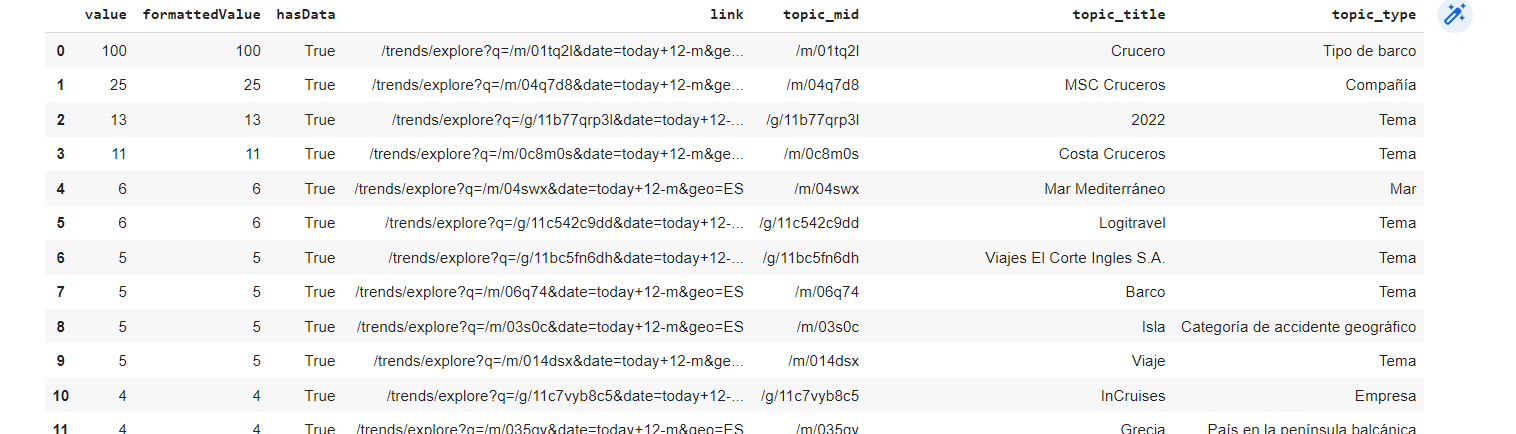
Gracias a los temas relacionados podemos ver que entidades está asociando Google con la palabra que nosotros le hemos indicado. Esto puede servirnos para enriquecer nuestros contenidos e intentar mejorar el contexto de estos.
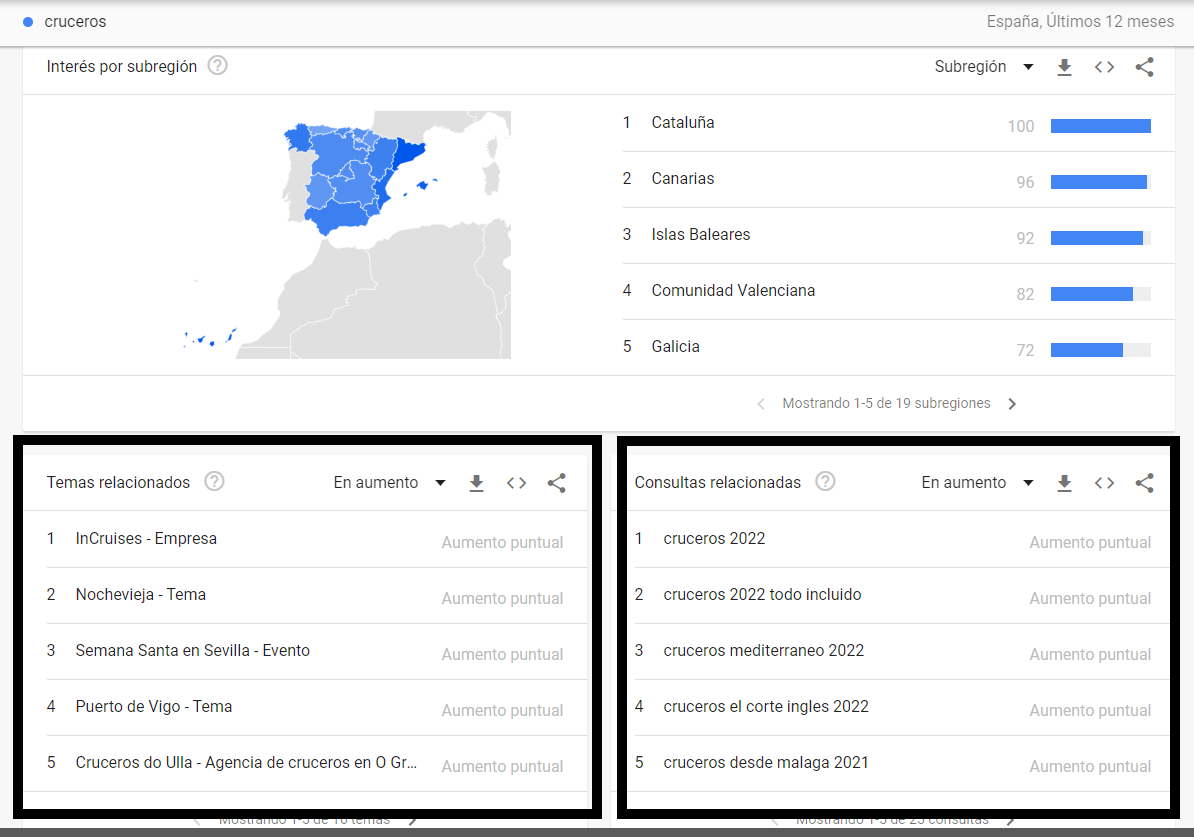
En cambio, en las consultas relacionadas se encuentran variaciones de la palabra que hemos establecido de origen.
Tanto estos datos como los que veremos en el apartado siguiente están directamente relacionados con los bloques que se muestran en Google Trends llamados “Temas relacionados” y “Consultas relacionadas”.
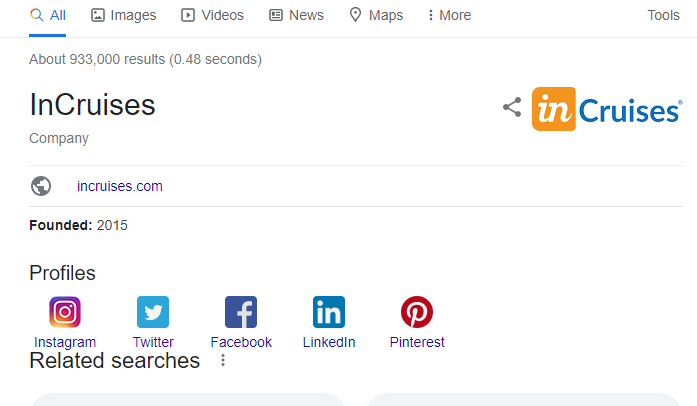
A parte de toda la información que se extrae en la consulta que hicimos más arriba, podemos ver el topic_mid, lo que sería el id asociado a la entidad mostrada dentro del Knowledge Graph de Google.
Aunque no parezca un dato demasiado relevante, nos permite conocer lo que se incluye en el Knowledge Graph que Google tiene asociado a dicha entidad.
Si utilizamos la siguiente estructura de url y añadimos el id de entidad que hemos obtenido, podemos ver lo siguiente:
https://www.google.com/search?q=love&kponly&kgmid=/g/11c7vyb8c5
Si quieres más información sobre esto, te recomiendo que eches un ojo a este artículo de Koray Tuğberk sobre el Knowledge Graph.
Related Queries
Como su propio nombre indica, podemos extraer las consultas relacionadas de la palabra original.
Analizar estos datos junto a los extraídos con related_topics nos permite conocer como las consultas relacionadas cambian totalmente las entidades con las que se asocian.
Al igual que el punto anterior, este método nos ofrece una gran cantidad de datos que podemos utilizar en la estrategia SEO de un proyecto, ya sea para enriquecer los contenidos o valorar la incorporación de nuevas secciones o páginas en la web que hablen de estos temas.
Siguiendo con el ejemplo anterior, también podemos especificar que tipo de datos queremos, desde las consultas que más están creciendo durante el periodo especificado o las más relevantes.
1. #Ejecutamos pytrends.related_queries()
2. pytrends.related_queries()
3.
4. #Indicamos que queremos consultas relacionadas en aumento durante el periodo
5. #establecido
6. analisis_tendencia = pytrends.related_queries()
7. analisis_tendencia.get("cruceros").get("rising")
Resultado:
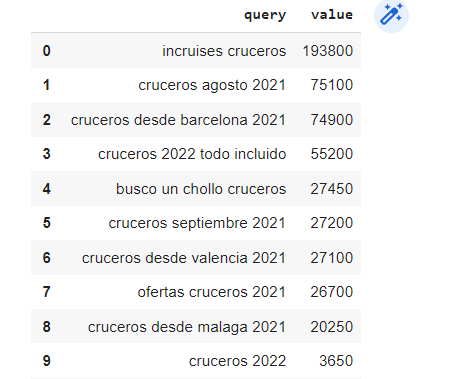
Analizando el resultado de esta consulta se pueden extraer bastantes conclusiones. En este caso, podemos interpretar como la consulta “cruceros 2022 todo incluido” está en plena tendencia, lo que nos puede dar una idea sobre hacia donde enfocar la creación de contenidos o la estrategia de SEO.
Análisis del top de consultas relacionadas para el periodo de tiempo que hayamos establecido:
1. #Ejecutamos pytrends.related_queries()
2. pytrends.related_queries()
3.
4. #Indicamos que queremos el top de consultas relacionadas durante el periodo
5. #establecido
6. analisis_tendencia = pytrends.related_queries()
7. analisis_tendencia.get("cruceros").get("top")
Resultado:
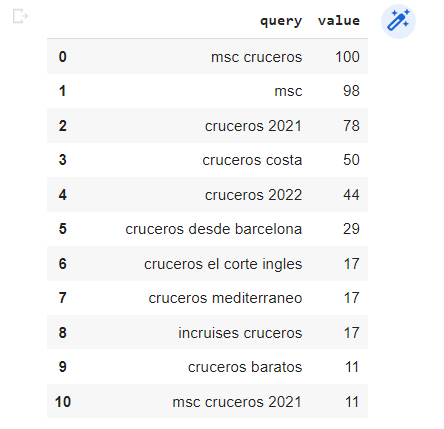
Trending Searches
Este método permite extraer las consultas en tendencia para una determinada zona geográfica. Desgraciadamente, solo funciona para determinados países, entre los que no está España.
Si trabajas con un proyecto internacional o una web de noticias en otro idioma, estos datos pueden ser realmente interesantes para cubrir noticias o eventos antes que otros medios o webs.
Se puede utilizar de la siguiente forma:
1. pytrends.trending_searches(pn="país del que queremos extraer datos")
Suggestions
El método suggestions nos ofrece la posibilidad de obtener una serie de consultas sugeridas para el término que hayamos elegido.
1. pytrends.suggestions("cruceros")
2. data_frame = pytrends.suggestions("cruceros")
3. data_frame = pd.DataFrame(data_frame)
data_frame
Para este caso hemos convertido la salida en un data frame que nos permita visualizar mucho mejor los datos extraídos, ya que la salida original es difícil de interpretar.
Resultado:
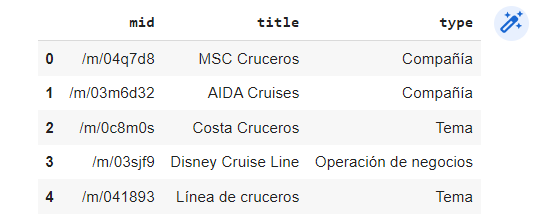
Aunque son pocas sugerencias, podemos hacernos una idea de lo que nos ofrecen estos datos. Como ves, obtenemos una serie de consultas sugeridas, con la entidad relacionada e incluso el id de entidad de Google.
Si analizamos los datos, podemos ver como Google tiene muy en cuenta la primera marca listada, relacionándola directamente con la palabra más general de ese sector.
Por otro lado, también podemos ver cuál es la entidad o consulta que Google más relaciona con la palabra de origen u otras consultas que podemos añadir en nuestro contenido para cubrir todo tipo de temas.
¿Qué posibilidades nos ofrecen las categorías establecidas por Google Trends?
Como antes comenté, Google Trends establece una serie de categorías para que podamos refinar mucho más los datos extraídos.
Estas categorías son las mismas que podemos ver a la hora de buscar un término en su web, pero para poder hacer uso de ellas a través de Pytrends, debemos conocer su número de referencia.
En este github tenéis un listado de todas las categorías utilizadas por Google Trends, incluyendo también un enlace al origen de estas.
Para poder entender el potencial de especificar una categoría, creo que lo mejor será verlo con un ejemplo.
Si por ejemplo establecemos como palabra o consulta de origen el término “panda” y hacemos referencia a la categoría número 66 (Animales), obtenemos el siguiente resultado:
1. #USO DE LAS CATEGORIAS 2. #Usando categoría 66 asdociada a animales 3. pytrends = TrendReq(hl="es") 4. lista_palabras = ["panda"] 5. pytrends.build_payload(lista_palabras, cat=66, timeframe="today 12-m", geo="ES") 6. pytrends.related_queries()
Resultado:
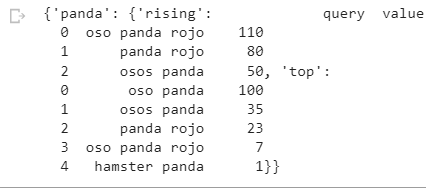
La solicitud refina la consulta y nos ofrece datos de tendencias sobre la palabra de origen dentro de dicha categoría. Esto evita que se incluyan otros términos relacionados por ejemplo con el mítico coche “seat panda”.
En cambio, si utilizamos la categoría 47, que está asociada a vehículos, los datos que obtenemos son los siguientes, mucho más específicos y relacionados con el vehículo.

Esto nos permite conocer como Google tiene en cuenta una consulta o palabra dada dentro de una categoría en concreto y que peso le da a la misma en función de la intención de búsqueda.
¿Cómo podemos utilizar la información obtenida en la extracción de datos con Pytrends?
Pytrends nos ofrece un gran número de posibilidades a la hora de extraer datos, pero no sirven de nada si no existe un objetivo posterior. He pensado en comentar algunas cosas que podemos hacer con ellos.
- Análisis de tendencias e intereses de los usuarios que podemos aprovechar: En cualquier proyecto que trabajemos nos interesará conocer los intereses de los usuarios a los que nos dirigimos y la tendencia de estos en el tiempo. Esto nos permitirá enfocar nuestra estrategia a nuevas tendencias o reforzar el trabajo ya realizado.
- Comparar intereses de marca o de productos: Aunque esto ya lo hemos comentado, podemos analizar el interés de los usuarios en nuestra marca y compararlo con la de nuestros competidores. De la misma forma podemos hacerlo con productos propios, etc.
- Analizar o comparar el interés de un determinado servicio o producto en un lugar concreto: Al poder geolocalizar las solicitudes, podemos comprobar el conocimiento o interés de una marca o producto en un lugar concreto. Muy útil para SEO local.
- Comprobar las entidades más relevantes para una consulta: Tener esta información nos ayudará a la hora de mejorar la semántica de nuestros contenidos, pero también en el enfoque de nuestra estrategia SEO.
- Tener datos actualizados y actuales relacionados con nuestro sector o producto: Gracias a esto podemos cubrir de forma actualizada tendencias de nuestro sector o crear nuevas urls que ataquen nuevas intenciones y consultas. Esta parte me parece muy importante para webs de noticias.
- Entender como afectan eventos económicos o de salud en los tipos de consulta e intenciones del usuario: Este es el reflejo de todos los cambios que se han visto en intenciones y búsquedas durante la pandemia.
- Crear nuestro propio dashboard donde monitorizar todo tipo de datos: Como ya habrás imaginado, todos estos datos podemos exportarlos a herramientas externas y generar un dashboard personalizado en función de las necesidades de cada uno.
Existen un gran número de opciones a la hora de aplicar estos datos. Estoy seguro de que ya te han venido a la cabeza todo tipo de formas de combinar todo esto y conseguir información valiosa y relevante para tu proyecto.
Alternativas a Pytrends
Para los que no quieren ver el código ni de cerca, he pensado en comentar varias alternativas que he visto investigando un poco.
Por un lado, la herramienta Keyword Tool cuenta con una sección en su herramienta llamada “Google Trends”, que te permite conocer algunos datos sobre una consulta dada.
Por otro lado, estos días también he visto que Andrew Charlton, un SEO bastante conocido en Reino Unido, ha compartido una forma de extraer los temas diarios en tendencia sin usar nada de código, directamente a un Google Sheets.
Conclusión
Como habréis visto, extraer datos con Pytrends en Python directamente desde Google Trends nos da infinitas posibilidades. Por supuesto, siempre podremos ir a la propia herramienta y comprobar los datos, pero si tienes una web muy grande o no quieres perder ese tiempo, puedes utilizar Pytrends para tener la información en el menor tiempo posible.
Espero que hayas disfrutado del artículo y que puedas utilizar estos datos de Google Trends en tus proyectos.
¡Nos vemos en las serps!
Otros recursos de interés:
