


Estoy seguro de que ya llevas un tiempo con problemas para indexar, tanto las urls de tu nuevo proyecto como para conseguir que Google indexe los cambios de contenido que has hecho en alguna de tus páginas. Pues he de decirte que ahora estás de suerte, puedes usar la API de Indexación de Google para notificar al bot de todas las novedades en tu web.
Desde que se inhabilitó la posibilidad de solicitar la indexación desde Search Console, he visto a mucha gente que se ha encontrado con estos problemas y se ha resignado esperando que el bot pase para ver los cambios.
Durante un tiempo me pasó lo mismo. Intentaba todo tipo de técnicas para forzar la indexación, desde enlazar la página desde un sitio clave de la web hasta crear enlaces, pero no obtenía resultado. Ya conocía la posibilidad de indexar una url a través de la API de Google, pero nunca lo había necesitado.
Por ello, empecé a investigar sobre la API y encontré una opción bastante fácil que me sirvió para conseguir unos resultados mucho mejores. En este artículo te contaré el proceso para darte de alta en la API y poder indexar tus urls con un sencillo script de Python.
Si no puedes esperar, puedes ir directamente a ver todo el proceso.
Tabla de contenidos
El presente y el posible futuro de la indexación
Aunque no es lo mismo, podemos decir que la indexación es la hermana del rastreo. Con el paso del tiempo Google ha ido refinando cada vez más su sistema de búsqueda con el objetivo de economizar el rastreo de todo internet. Ellos mismos lo dicen, su índice de búsqueda contiene cientos de miles de millones de webs, que en total superan los 100 mil millones de Gb (Imagina la inversión en equipos que esto supone).
Internet se ha convertido en la nueva biblioteca a la que todos podemos acceder desde cualquier parte, pero sin un límite de préstamos ni catálogo. Google descubre todas estas páginas web para facilitar el acceso a la información por parte del usuario, pero en el “WebSpam Report” de 2019 podíamos ver cómo más de 25 mil millones de estas páginas descubiertas en un día son catalogadas como spam.
Entre los objetivos más prioritarios de Google está conseguir que este índice sea lo más pequeño posible y, sobre todo, que solo contenga resultados de calidad. Por supuesto y como te habrás imaginado, la API podría actuar como el filtro perfecto para evitar el rastreo de páginas web que no aportan nada al usuario y por tanto, que el contenido indexado sea de la máxima calidad.
Aunque hoy en día el rastreo sigue funcionando como todos conocemos, crawleando los enlaces y descubriendo páginas a medida que pasa por cada una de ellas. Con un sistema de API la indexación de contenido spam ya no sería tan fácil.
Evitar todo este spam y ahorrar recursos en el rastreo de la web podría ser la base perfecta para que Google no tuviese que invertir una gran cantidad de dinero en mejorar sus sistemas. Por otro lado, evitarían en gran medida que el bot tuviese que viajar por las páginas webs descubriendo las urls y gastando recursos en dicha travesía.
Por supuesto, existen muchas otras cosas que podrían marcar la dirección hacia esta nueva forma de indexación, pero eso ya daría para otro artículo. Al igual que todo esto solo es una idea de cómo podrían cambiar las cosas con el paso del tiempo, pero si quieres más información al respecto, te recomiendo que eches un ojo a este artículo de Kevin Indig donde trata el tema de forma mucho más detallada.
¡Bueno, vamos al lío!
Los problemas de indexación en la actualidad
Desde hace un tiempo en el mundo SEO hemos visto cómo se han sucedido múltiples problemas de indexación y que incluso han afectado directamente a la canonicalización de páginas.
Solo en 2020 estimamos que ya hemos sufrido hasta 3 bugs de indexación. El primero el 23 de Abril y el último era comunicado por la cuenta de twitter del propio Google el 2 de Octubre.
Quizás este último ha sido el que más dolores de cabeza ha causado a la comunidad, donde también pudimos ver a muchos profesionales quejándose de este bug. Aunque no se han relacionado, el día 14 de octubre la comunidad se encontraba con la sorpresa de que se había deshabilitado la opción de “Solicitar indexación” en Search Console.
Aunque una semana después de este comunicado se daba por solucionado este último problema de indexación, la solicitud desde Search Console no se había habilitado, y así sigue hasta día de hoy.
Google API Indexing. Qué debes saber.
Para los que no lo sepan, la API de indexación permite avisar directamente Google de cualquier cambio que hayas hecho en una url, desde notificar la creación de nuevas páginas en tu web hasta la eliminación de las mismas.
Textualmente y como ellos mismos informan en su web, la API de indexación tiene las siguientes funciones:
- Actualizar las urls
- Retirar urls
- Ver el estado de la solicitud
- Enviar solicitudes de indexación en bulk o lote.
Además, hay que añadir que Google informa que esta API solo funciona para el rastreo de páginas que incluyan datos estructurados relacionados con “JobPosting” o “BroadcastEvent”, pero desde que se creó funciona para forzar la indexación de cualquier tipo de url.
Como usar la API de Indexación y conseguir que funcione
En este apartado veremos el proceso paso a paso que debes seguir para utilizar la API de Indexación de Google y por último, utilizaremos un script de Python en Google Colab para mandar las urls de forma muy sencilla.
¡Empezamos!
Lo primero que debes hacer es crear un proyecto desde el servicio de APIS de Google, habilitar la API y descargarte la API KEY que necesita el proyecto para funcionar.
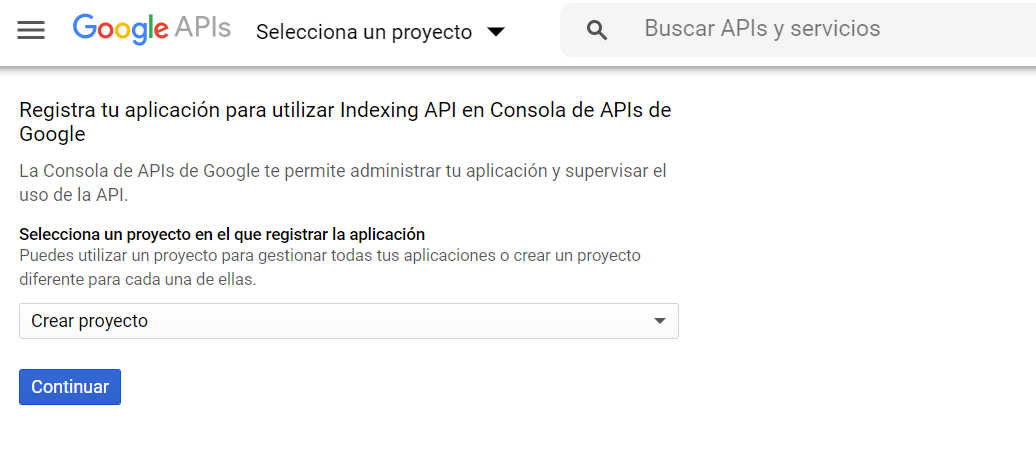
En el momento que crees el proyecto te saldrá una ventana como esta donde podrás ponerle nombre.
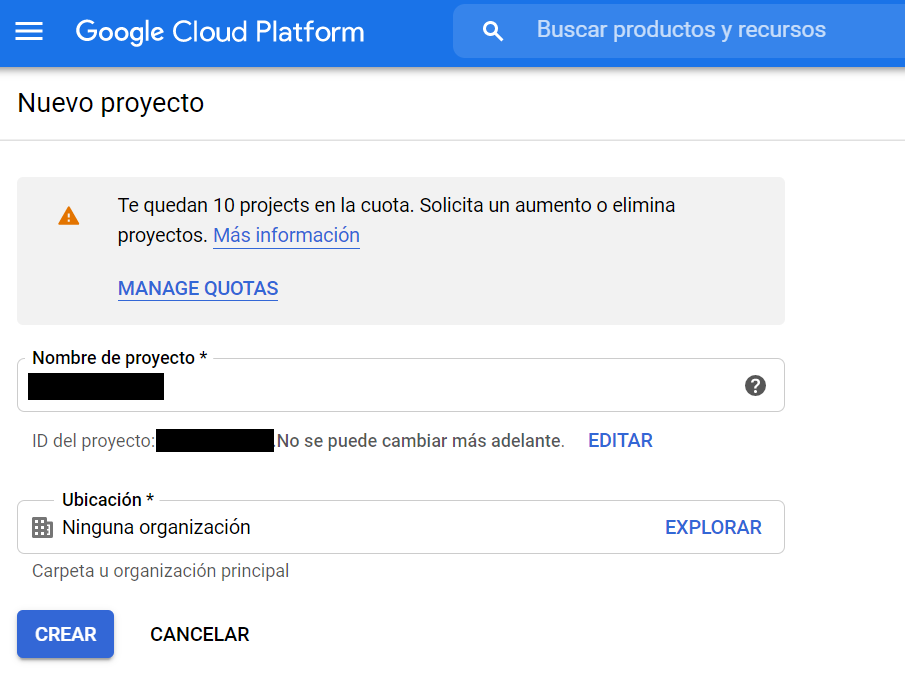
Como ves en la imagen, tienes disponibles hasta 12 proyectos distintos con una sola cuenta en función de lo que necesites. Después de darle a “crear” te saldrá otra ventana donde se muestran las cuentas de servicio asociadas a tu nuevo proyecto. En esta ventana debes darle a “Crear cuenta de servicio” para poder obtener tu API KEY.
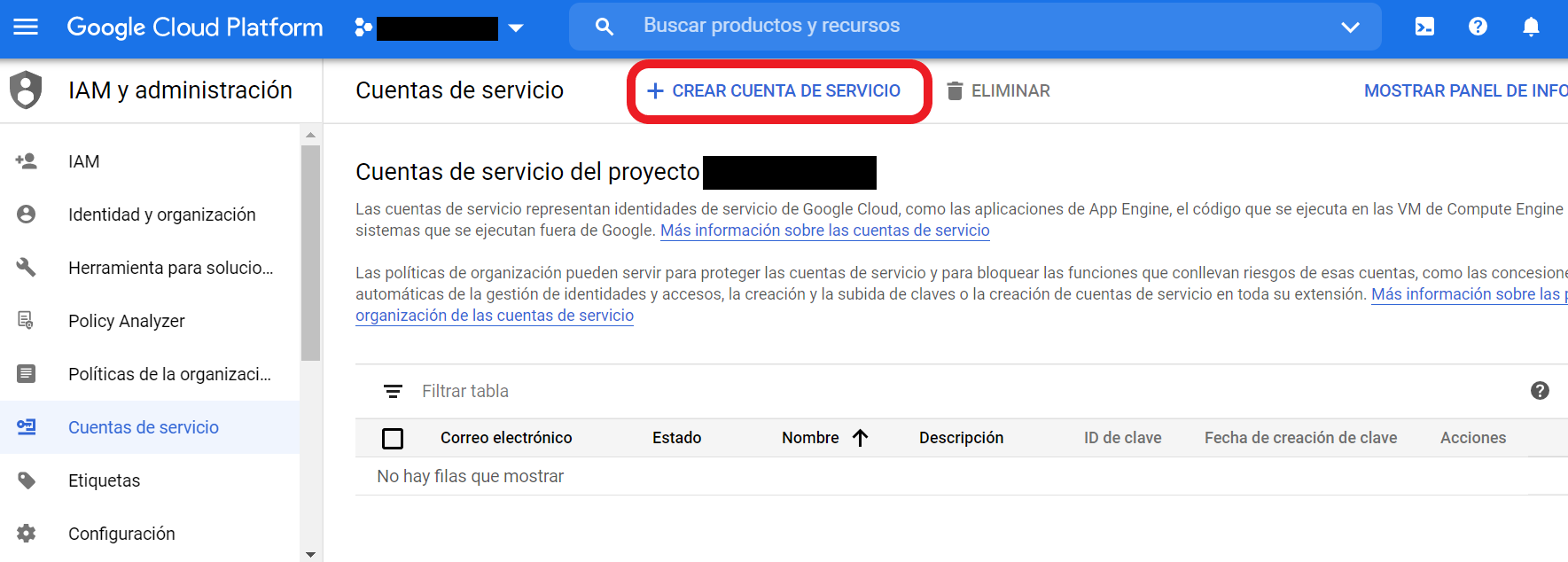
En ese momento te aparecerá una nueva ventana como verás en la siguiente imagen donde podrás ponerle nombre a tu nueva cuenta y se creará un ID con ese mismo nombre. Puedes darle a “Crear” para continuar con el proceso.
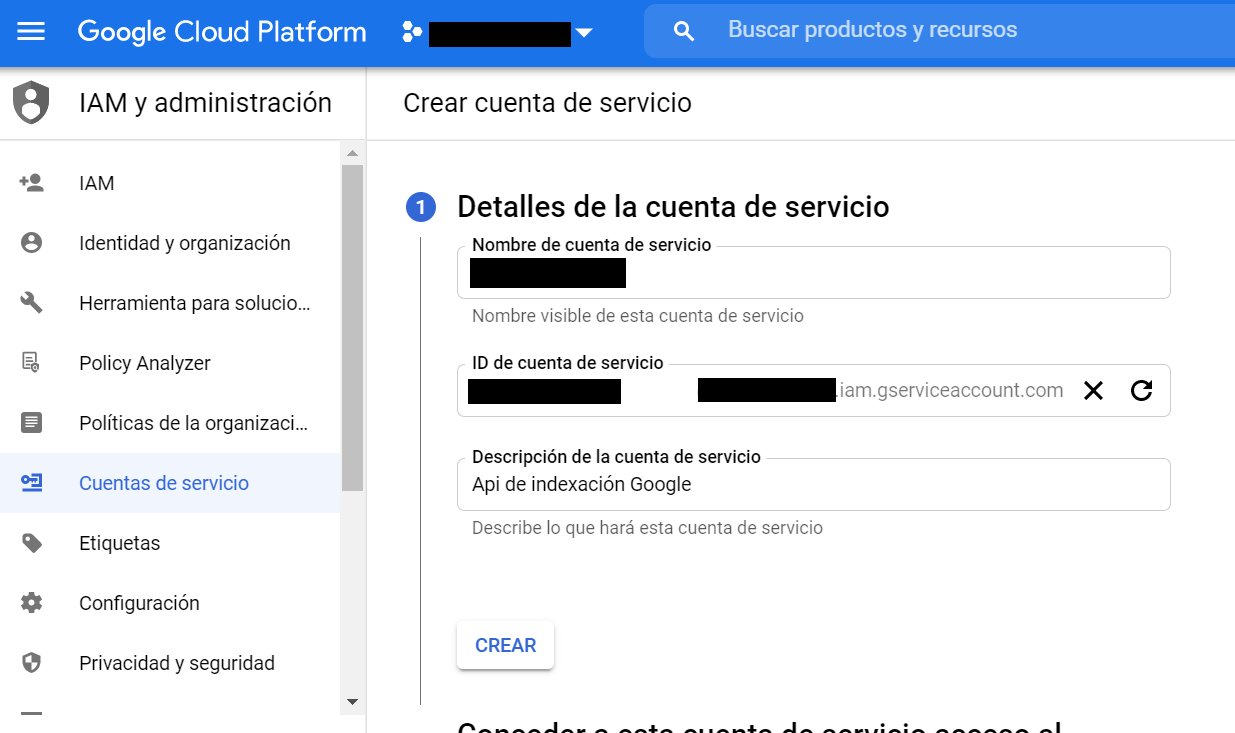
En el segundo paso tendrás que dar acceso a esta cuenta de servicio a tu proyecto. Para que no tengas problemas debes darle un rol de “Propietario”. Este lo encontrarás dentro de la sección “Proyecto”.
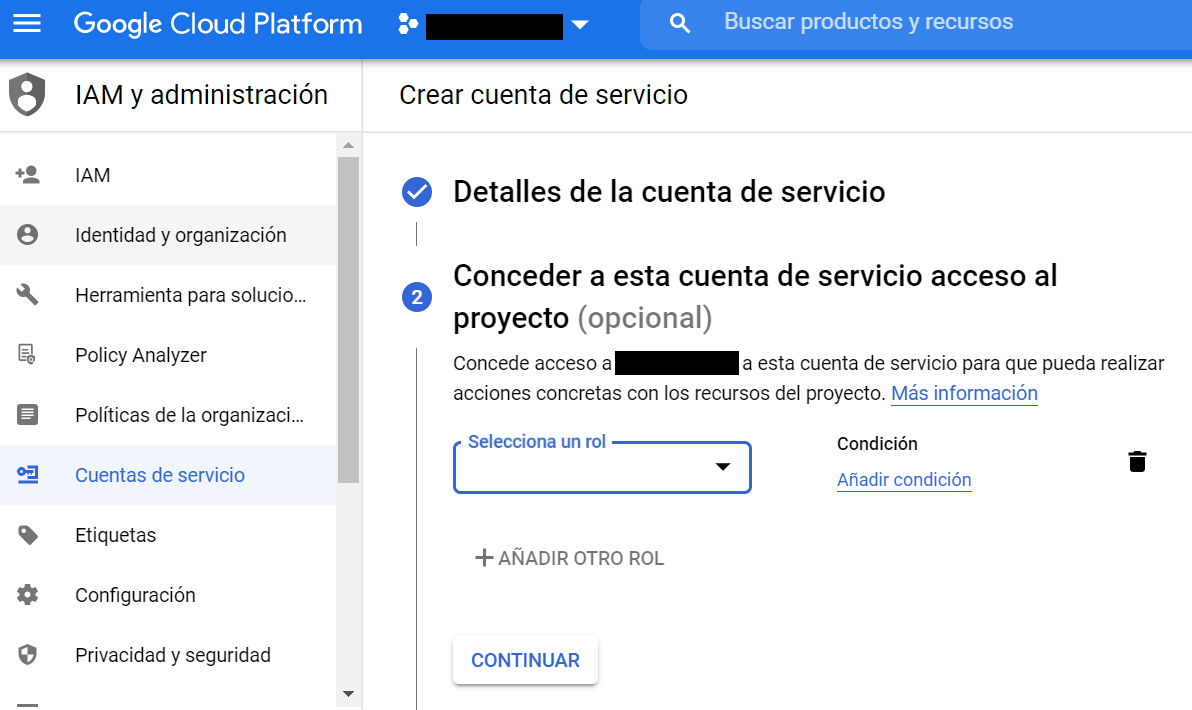
En el paso número 3 no tienes que hacer nada. Te recomiendo que le des a “Listo” sin tocar ningún parámetro. En el momento que hayas completado los 3 pasos te saldrá la siguiente imagen, donde verás que se ha creado una cuenta de servicio nueva para tu proyecto.
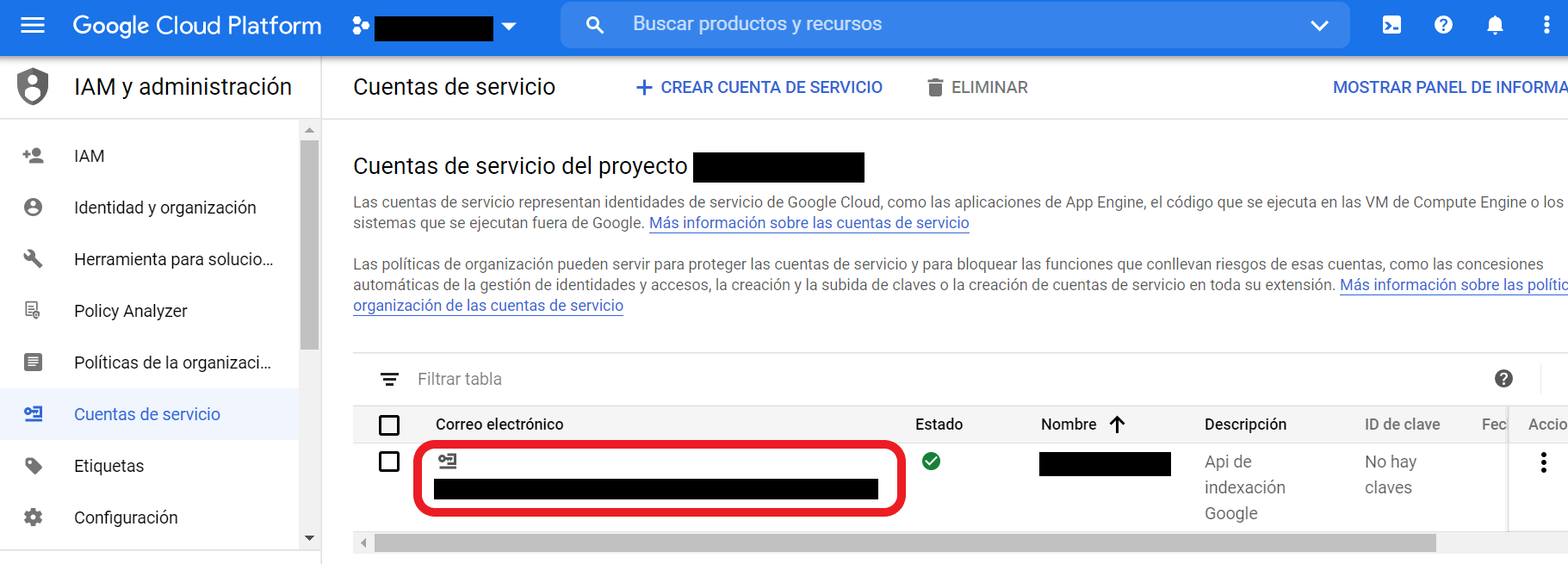
Como verás, se crea un correo electrónico asociado a dicha cuenta. Este correo es realmente importante, ya que debes añadirlo como propietario a la cuenta de Search Console en la que tengas verificada la web del proyecto donde vas a utilizar la API. Ten en cuenta que si quieres usarla para más de una web, tendrás que añadirla como propietario en cada una de ellas.
Desde Search Console y dentro de la propiedad donde quieras utilizar la API debes ir a la sección “Ajustes” > “Usuarios y permisos”. A la derecha de la configuración de propietario verás 3 puntos en vertical donde te saldrá una ventana emergente que indica “Administrar a los propietarios de la propiedad”.
Cuando pulses esta ventana emergente te llevará a la versión antigua de Search Console, donde podrás añadir un nuevo propietario.
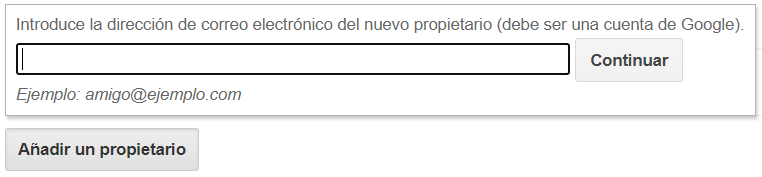
En este campo debes añadir el correo que te había proporcionado la cuenta de servicio y darle a “Continuar”. De esta forma le estarás dando acceso como propietario a la API para poder enviar a indexar todas las urls que quieras a través de tu Search Console.
Después de esto debes volver a la ventana donde aparecían tus cuentas de servicio y generar la API KEY que utilizarás para enviar las urls.
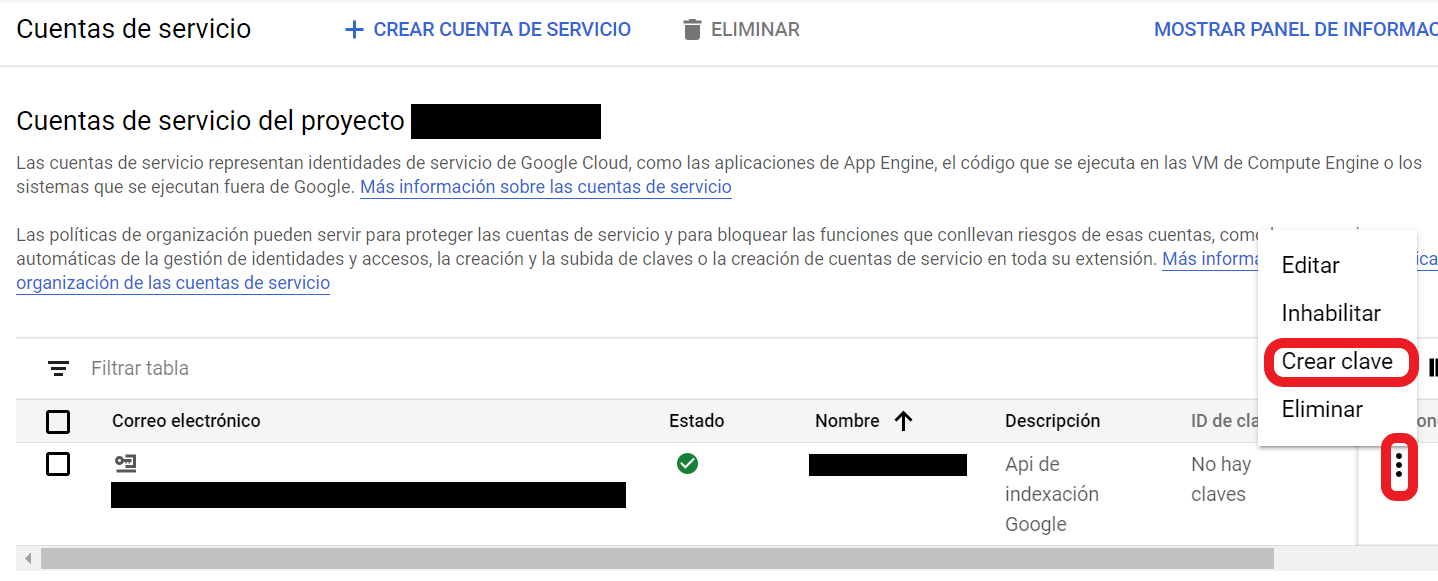
En este momento te aparecerá una ventana emergente donde tendrás que crear tu API KEY en formato JSON. En el momento que le des a “Crear” se descargará un archivo en tu ordenador que tendrás que usar en Google Colab para poder utilizar la API.
Por último, debes acceder a la librería de APIs de Google y buscar “Indexing API”. Verás que te aparece la propia API de indexación que tendrás que habilitar.
Después de habilitar la API, con el archivo JSON descargado en tu ordenador y el correo electrónico añadido en tu Search Console tendrás que ir Google Colaboratory y crear un nuevo cuaderno.
Google Indexing API con Python
En tu nuevo cuaderno de Google Colab debes subir el archivo JSON generado con tu API KEY. Verás que a la izquierda tienes un menú donde una de las secciones se llama “Archivos”, desde la que podrás subir cualquier documento que quieras utilizar en tu script.

Con el JSON que contiene la API KEY subido a tu nuevo cuaderno solo tendrás que copiar el siguiente código y completar un par de pasos más para que funcione.
from oauth2client.service_account import ServiceAccountCredentials
import httplib2
SCOPES = [ "https://www.googleapis.com/auth/indexing" ]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
# service_account_file.json is the private key that you created for your service account.
JSON_KEY_FILE = "(RUTA DEL ARCHIVO JSON SUBIDO A TU CUADERNO)"
credentials = ServiceAccountCredentials.from_json_keyfile_name(JSON_KEY_FILE, scopes=SCOPES)
http = credentials.authorize(httplib2.Http())
content = """{
"url": "(URL QUE QUIERES ENVIAR A INDEXAR)",
"type": "URL_UPDATED"
}"""
response, content = http.request(ENDPOINT, method="POST", body=content)
print(response)
print(content)
Para conocer la ruta del archivo subido a tu cuaderno solo tienes que ir a la ventana “Archivos” y como verás, aparece tu JSON subido. Si clicas sobre los 3 puntos verticales a la derecha del nombre te dará la opción de “Copiar ruta”. Esta ruta debes incluirla en el código anterior y añadir la url que quieres enviar a indexar.
En el momento que tengas ambas cosas solo tendrás que darle a ejecutar para que funcione. Si has seguido todos los pasos correctamente verás que debajo del script saldrá una respuesta, en la que debes comprobar que se incluye el mensaje “Status: 200”. De esta forma sabrás que ha funcionado.
¡Ya lo tienes! Ahora con solo modificar la url que quieres enviar puedes forzar la indexación. Aquí tienes un resumen de las cuotas diarias y por minuto que tienes con la API, pero a no ser que utilices el script en lote, es difícil agotarlas.
Igualmente, este no es el único método que existe para hacerlo. David Sottimano también ha creado un código en Node JS con el que utilizar la Indexing API. Por otro lado, también en los últimos días hemos visto como otros SEOs de la comunidad española han expuesto métodos a través de twitter para hacerlo con Python, como es el caso de Natzir Turrado.
Como ves, existen muchas formas de hacerlo, pero para mí esta ha sido la menos complicada. ¡Espero que te haya gustado y puedas utilizarlo sin problemas!
Otros recursos interesantes:
- https://developers.google.com/search/apis/indexing-api/v3/quickstart
- https://www.google.com/search/howsearchworks/mission/creators/
- https://webmasters.googleblog.com/2020/06/how-we-fought-search-spam-on-google.html
- https://www.google.com/search/howsearchworks/crawling-indexing/
- https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/34570.pdf
