


En Premium Leads estamos creando un nuevo conjunto de soluciones que incorporan los últimos avances en diversos campos de la Inteligencia Artificial como el reconocimiento de voz (ASR) o el procesado de lenguaje natural (NLP), con la meta de liderar este sector en nuestro entorno.
En la actualidad, una de las arquitecturas Deep Learning (de redes neuronales profundas) en el estado del arte de ASR (SOTA) es la llamada Wav2Vec. Esta ha sido creada por el departamento de IA de Facebook e integrada recientemente en la estupenda librería HuggingFace Transformers.
El desafío Fine-Tuning
La última semana de marzo 2021 la organización HuggingFace celebró una semana de “fine-tuning”, con el objetivo de crear modelos de ASR en múltiples lenguajes a partir del modelo Wav2Vec. Han querido poner especial énfasis en lenguas para las que no existen grandes “datasets” con los que poder entrenar modelos ASR tradicionales. Como no podía ser de otra manera, ¡nuestro equipo de Premium Leads se apuntó al desafío!
El primer paso fue prepararnos para participar en el desafío, y nos pusimos las pilas para entender en profundidad cómo funciona el modelo ASR Wav2Vec.
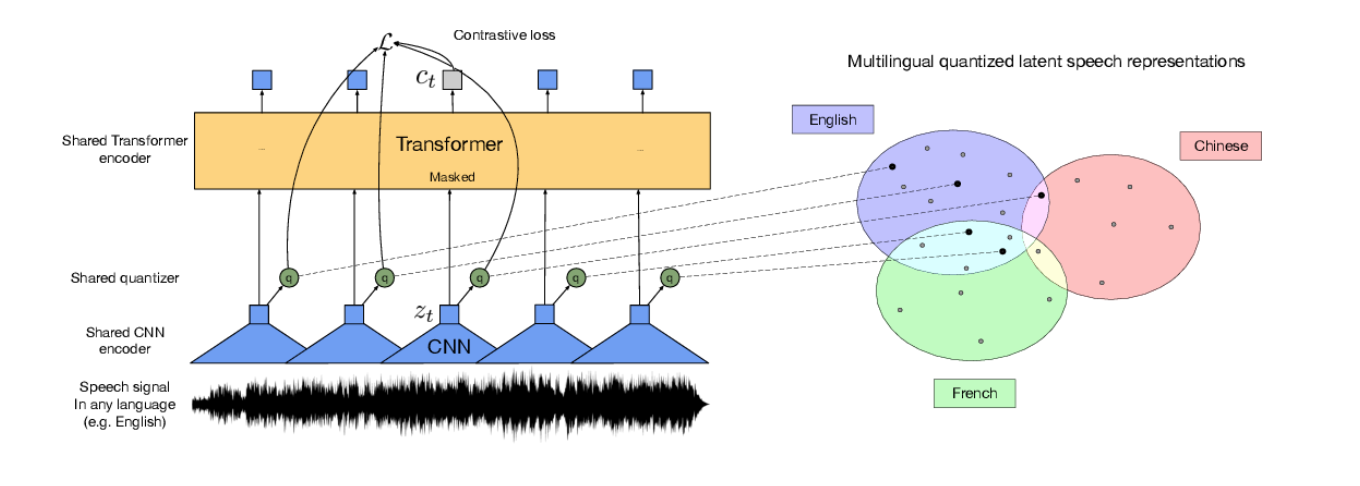
La idea es relativamente sencilla. Se trata de la combinación de dos modelos: una red convolucional (CNN) cuya salida se conecta a otra red de tipo Transformer. Pero el diablo está en los detalles, ya que los modelos ASR tienen que procesar cantidades ingentes de datos. Normalmente un espectrograma* Mel por cada 25 milisegundos de audio.
*El espectrograma es como una imagen que muestra la amplitud del audio por cada frecuencia y muestra temporal.
Para resolver este problema, los científicos de Facebook han diseñado capas especiales de cuantificación y otras optimizaciones que permiten entrenar este enorme modelo en una GPU de escritorio, al menos con una cantidad limitada de datos.
¿Cómo obtener buenos resultados en ASR sin una cantidad ingente de datos?
Ahí es donde entra el procedimiento de pre-entrenamiento promovido por el célebre Yann LeCun y que sigue un método similar al modelo BERT que revolucionó el campo de NLP en 2017.
La idea es enmascarar el audio de forma aleatoria, configurando la red para que aprenda a rellenar los huecos y predecir el audio enmascarado. Esta red produce una representación vectorial cuantificada que puede ser usada después para ASR o con otros propósitos. La ventaja de este método es que permite el entrenamiento con cualquier audio, incluso en múltiples lenguajes y sin necesidad de ningún tipo de costoso etiquetado. Y eso es lo que ha hecho Facebook, ¡entrenando el modelo con miles de horas de audio en 53 idiomas! Este modelo se denomina XSLR-53 y se ha liberado como OpenSource.
El resultado: la representación del audio que sale de la red es capaz de interpretar múltiples tonos de voz, acentos, tolerar ruido de fondo, etc.
Volviendo a la Fine-tuning week, el objetivo en concreto fue el de aplicar el model XSLR-53 integrado en HuggingFace para crear modelos de ASR en todos los idiomas posibles, en concreto en los idiomas presentes en CommonVoice*.
*CommonVoice es una iniciativa de Mozilla para construcción de un dataset multilingüe para ASR y de un algoritmo de ASR de código abierto, llamado Mozilla DeepSpeech. Aunque DeepSpeech es un modelo de ASR muy eficiente y preciso, requiere una cantidad ingente de datos para su entrenamiento.
Construyendo nuestro propio modelo para la lengua gallega
Aprovechando que Facebook ha liberado un modelo XSLR específico para español y siguiendo el foco en las lenguas con escasez de datos, optamos por participar creando un modelo para gallego. Que se note que ¡somos gallegos en cuerpo y alma!
El primer problema que nos encontramos para hacer el fine-tuning en gallego es que CommonVoice todavía no dispone de un dataset descargable. Por suerte, encontramos un dataset recolectado por OpenSLR y creado por Google con unas diez horas de audio con transcripciones de alta calidad. Con este dataset, lanzamos el fine-tuning usando un notebook de Google Colab.
Después de unos pequeños ajustes como, por ejemplo, filtrar los caracteres no incluidos en el alfabeto gallego, obtuvimos una precisión de un 83% de palabras (WER 16). Esto es más que aceptable teniendo en cuenta la escasez de datos disponibles y constituye todo un hito para nuestra lengua. El modelo se puede encontrar aquí:
https://huggingface.co/diego-fustes/wav2vec2-large-xlsr-gl
Estamos preparando modelos en otros lenguajes nacionales como el catalán, aunque requieren de una infraestructura mayor al existir grandes conjuntos de datos. Esto sólo es el principio y nuestros planes son mejorar el SOTA de muchos algoritmos en español, gallego y demás lenguas nacionales.
¡Permaneced atentos!
