At Premium Leads we are creating a new set of solutions that incorporate the latest advances in various fields of Artificial Intelligence, such as speech recognition (ASR) or natural language processing (NLP), with the goal of leading this sector in our environment.
Currently, one of the Deep Learning architectures (deep neural networks) in the state of the art of ASR (SOTA) is called Wav2Vec. This has been created by Facebook’s AI department and recently integrated into the great HuggingFace Transformers library.
Table of Contents
The Fine-Tuning Challenge
On the last week of March 2021 the HuggingFace organization held a “fine-tuning” week, with the aim of creating ASR models in multiple languages from the Wav2Vec model. They wanted to place special emphasis on languages for which there are no large “datasets” to train traditional ASR models with them. How could it be otherwise, our Premium Leads team joined the challenge!
The first step was getting ready to take part, and we got prepared to fully understand how the ASR Wav2Vec works.
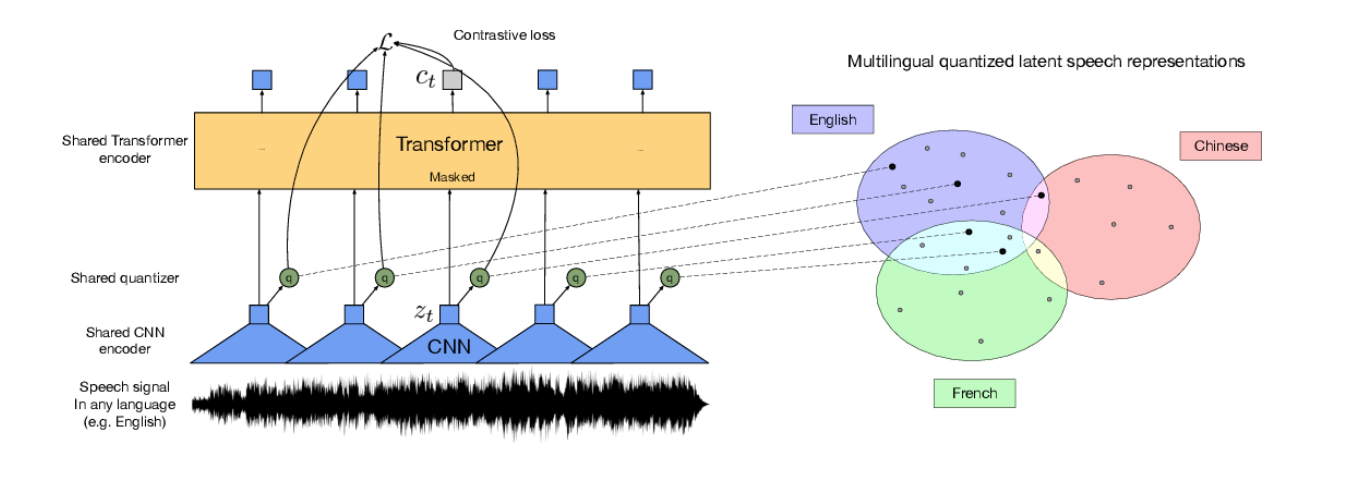
The idea is relatively simple. It is the combination of two models: a convolutional network (CNN) whose output is connected to another Transformer-type network. But the devil is in the details, as ASR models have to process massive amounts of data. Typically one Mel spectrogram* for every 25 milliseconds of audio.
*An spectrogram is like an image that shows the amplitude of the audio for each frequency and temporary sample.
To solve this problem, Facebook scientists have designed special quantization layers and other optimizations that allow this huge model to be trained on a desktop GPU, at least with a limited amount of data.
How to get good results in ASR without a huge amount of data?
This is where the pre-training procedure promoted by the famous Yann LeCun comes in and which follows a method similar to the BERT model that revolutionized the field of NLP in 2017.
The idea is to mask the audio randomly, configuring the network so that it learns to fill in the gaps and predict the masked audio. This network produces a quantized vector representation that can be used later for ASR or other purposes. The advantage of this method is that it allows training with any audio, even in multiple languages and without the need for any expensive tagging. And that’s what Facebook has done, training the model with thousands of hours of audio in 53 languages! This model is called XSLR-53 and has been released as OpenSource.
The result: the representation of the audio coming out of the network is capable of interpret multiple tones of voice, accents, tolerating background noise, etc.
Going back to Fine-tuning week, the specific objective was to apply the XSLR-53 model integrated in HuggingFace to create ASR models in all possible languages, specifically in the languages present in CommonVoice*.
*CommonVoice is a Mozilla initiative to build a multilingual ASR dataset and an open source ASR algorithm, called Mozilla DeepSpeech. Although DeepSpeech is a very efficient and accurate ASR model, it requires a huge amount of data for training.
Building our own model for the Galician language
Taking advantage of the fact that Facebook has released a specific XSLR model for Spanish, and following the focus on languages with limited data, we opted to participate by creating a model for Galician. Because we are in fact proud Galicians!
The first problem we encountered when doing fine-tuning in Galician is that CommonVoice still does not have a downloadable dataset. Luckily, we found a dataset collected by OpenSLR and created by Google with about ten hours of audio with high-quality transcripts. With this dataset, we launched the fine-tuning using a Google Colab notebook.
After some small adjustments such as, for example, filtering the characters not included in the Galician alphabet, we obtained an accuracy of 83% of words (WER 16). This is more than acceptable considering the scarcity of available data and constitutes a milestone for our language. The model can be found here.
We are preparing models in other national languages such as Catalan, although they require a larger infrastructure as there are large data sets. This is only the beginning and our plans are to improve the SOTA of many algorithms in Spanish, Galician and other national languages.
Stay tuned!
