


¿Te has preguntado por qué algunas canciones tienen un sonido más alto que otras? ¿Por qué parece que el artista esté intentando rompernos los tímpanos? ¡Sabía que no era el único! La respuesta -aparente- a este grandísimo dilema para la humanidad la dieron algunos productores e ingenieros de sonido, que alertaron de que se estaba produciendo un fenómeno en las discográficas: Loudness War.
Dicho fenómeno ocurría tanto en la grabación de nuevos discos como en la remasterización de los mismos: se estaba aumentando progresivamente el volumen de las canciones, haciendo que estas perdieran calidad y definición. Los detalles técnicos sobre el por qué ocurre esto, conocido como Loudness War, los podéis leer por aquí. En este post nos centraremos en otra cosa: hablaremos de extracción de datos y validación de hipótesis.
Por mucho que a mí me gustara esta teoría, y creyera en la palabra de ciertos expertos (que poco o nada tenían que ganar al decir estas cosas), no podía quitarme de la cabeza que, en realidad, era su palabra contra la de las discográficas. Como buen analista, necesitaba tener pruebas con las que entender si esto estaba ocurriendo de verdad o no, necesitaba validar las hipótesis. Así que me dediqué a investigar de dónde podría sacar este tipo de información para una muestra relativamente grande de canciones. Al final, como no podía ser de otra manera, llegué hasta Spotify.
Para alguien que disfruta casi por igual de los datos y de la música, la
API de Spotify
es como entrar en un paraíso. La cantidad de información que puedes extraer de
ahí es prácticamente infinita, y muy variada.
Para obtener la información que necesitaba para mi análisis debía realizarlo
en dos tiempos:
- Recolectar una base de metadatos de canciones (nombre, artista, album, id…) que fuese lo suficientemente grande para considerarlo una muestra.
- Extraer la información de features (loudness, danceability, energy…) en relación a esas canciones.
Extracción de datos de la API de Spotify
Voy a hacer un pequeño walkthrough por el código con el que extraje estos datos y así podáis entender mejor el proceso:
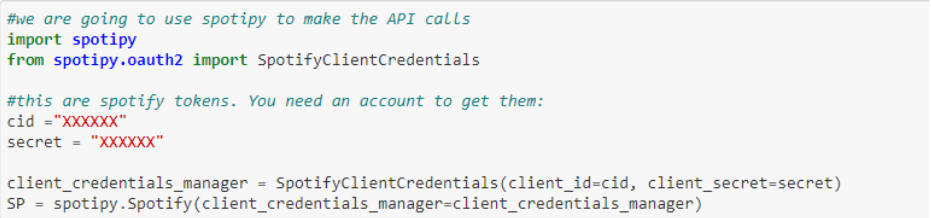
Llamada a la API de Spotify
En primer lugar, tenemos que llamar a la API de Spotify con el módulo spotipy. Necesitaremos una cuenta de desarrollador en Spotify para poder realizar las llamadas, pero es un paso súper sencillo. Con eso podremos conseguir el Client Id y Client Secret que almacenaremos como una variable, para utilizar más adelante.
Crear una lista de canciones por décadas
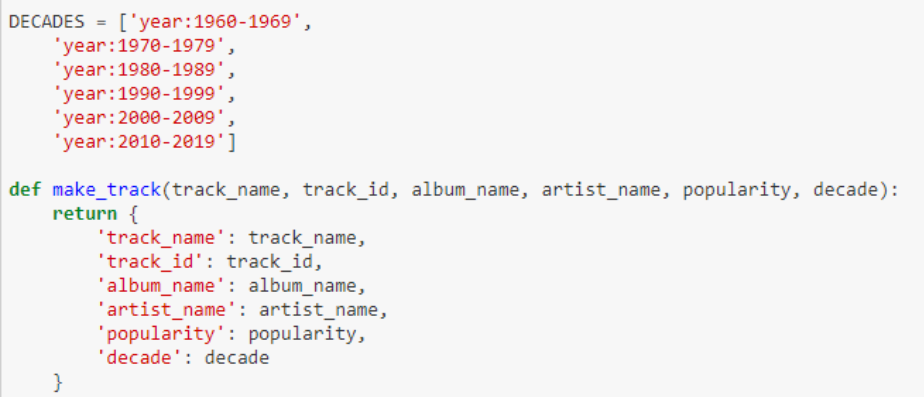
Mi intención era recoger canciones de diferentes décadas, para poder
estudiar así la evolución de esta tendencia. Por ello,
ahora debemos crear una
lista con los años que componen esas décadas
(este es el formato que entiende Spotify como década). Como podéis observar,
la función make_track lo que hace es crear la estructura que yo
quiero obtener como base de datos de canciones. Esto nos será útil en el
siguiente paso.
*Tip: Para tenerlo todo más ordenado lo que haremos es
enlazar en cada canción la década correspondiente, algo en lo que
nos ayudará la función get_first_year.
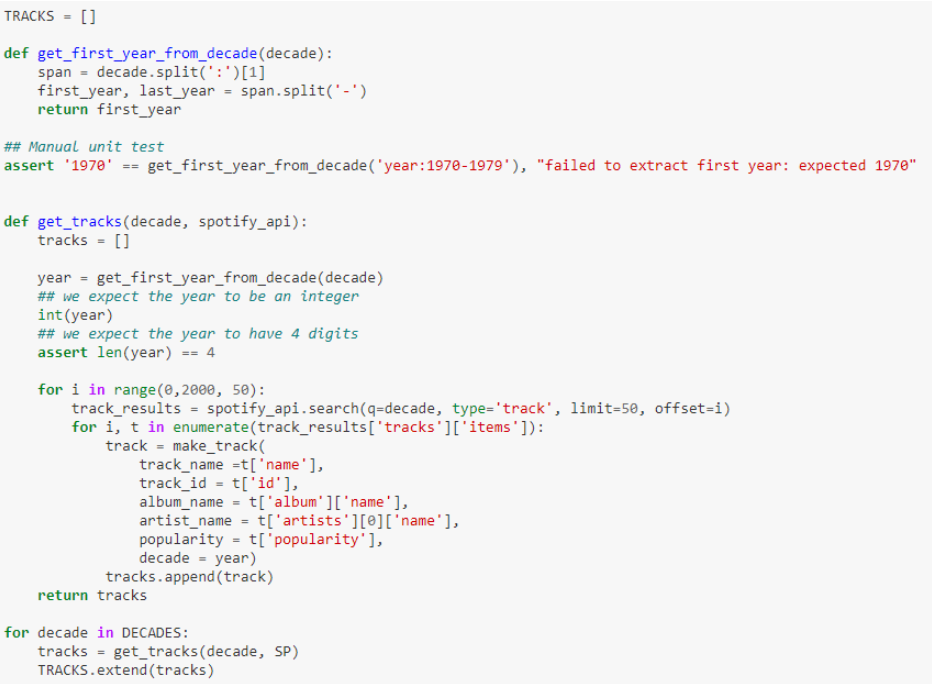
Obtención de datos
La función get_tracks es donde se cocina realmente lo más
importante, que es la
creación propia de la llamada a Spotify. Utilizaremos por último esta función en un
loop para que nos devuelva los datos que queríamos.
Ya tenemos nuestra base de datos con los metadatos de unas 12.000 canciones (2.000 por década). Ahora toca la parte divertida: Almacenar estos datos y volver a llamar a Spotify para recoger los features por ID. Obtendremos algo parecido a esto:
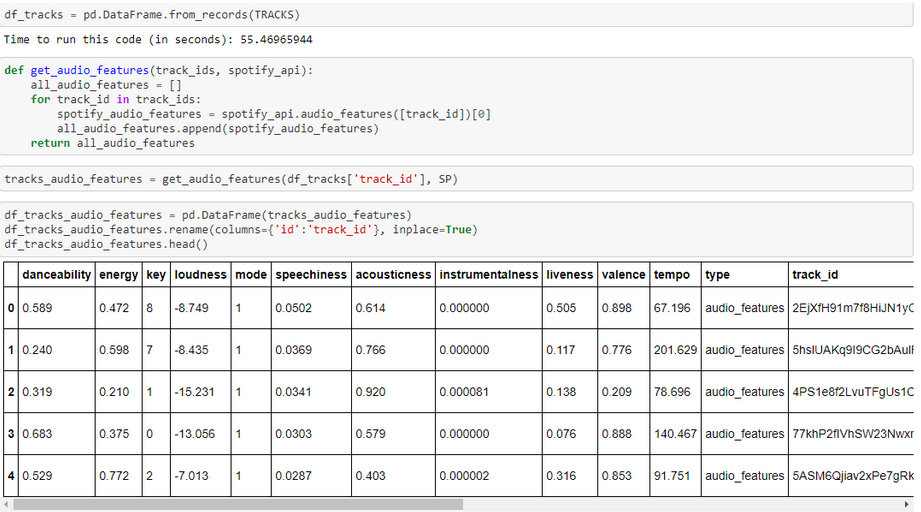
Lo que vemos aquí son todas esas características que van asociadas a una canción (en este caso, a un ID) y que más tarde utilizaremos para nuestro análisis.
Creación de nuestra base de datos
Sólo nos quedará realizar el join con el anterior dataframe que hemos creado. Esto nos permitirá tener tanto la información del artista o la década de la canción, como de las características que vamos a explorar. Cuando tengamos estos datos, lo que haremos será crear un archivo CSV que utilizaremos para trabajar en nuestra plataforma de visualización de datos, en este caso Data Studio.
Visualización de datos con Google Data Studio
Google Data Studio es una herramienta que me gusta mucho por dos razones fundamentales: es gratis y te permite una flexibilidad comparativamente grande para hacer las cosas que tú quieres.
Aquí puedes ver el resultado final de este experimento, en el que incluso he preparado un pequeño modo interactivo para que cada uno busque sus artistas o canciones favoritas. Pero quedaos conmigo antes de poneros a jugar porque ahora viene la parte más importante de todo este post: cómo representar correctamente los datos que hemos extraído.
¿Por qué es esta la parte más importante? Porque dependerá de este paso el que la gente pueda entender lo que estás queriendo transmitir o no. Y unos datos magníficos mal comunicados sirven más bien de poco. Mi idea aquí fue intentar simplificar al máximo los gráficos para facilitar la comprensión de una información que es esencialmente especializada. Para ello, utilicé 3 gráficos para mostrar claramente si la hipótesis inicial era correcta o errónea. Vamos con el primero, el histograma:
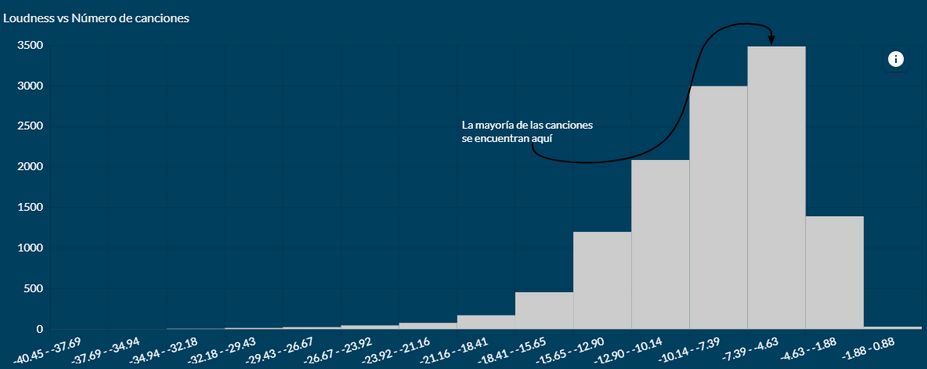
Esto ya nos está dando muchísima información. La distribución de la muestra se encuentra principalmente en los tramos más altos, es decir, con mayor volumen. Parece que la teoría de la conspiración se está consolidando. Veamos si también aciertan en la evolución temporal, ya que todo esto parece empezar con la inserción del CD en el mercado:

Según el gráfico, parece que de los años 60 a los 80 el rango dinámico de las canciones se fue ampliando progresivamente, pero a partir de los 90 vemos cómo el volumen aumenta y el rango dinámico va decreciendo, siendo los 2000 el peor punto de esta serie.
Conclusión: La batalla del volumen es real
¿Qué quiere decir esto exactamente? Pues que Wikipedia, como siempre, tenía razón. Los críticos del volumen en la música tienen aquí sus argumentos muy bien cubiertos, pues como hemos comprobado la música ha sufrido un proceso de ‘volumenización’ en las últimas décadas que le ha hecho perder gran parte de su rango dinámico y por tanto, de su rango emocional.
Veamos algunos ejemplos que representan claramente este proceso:
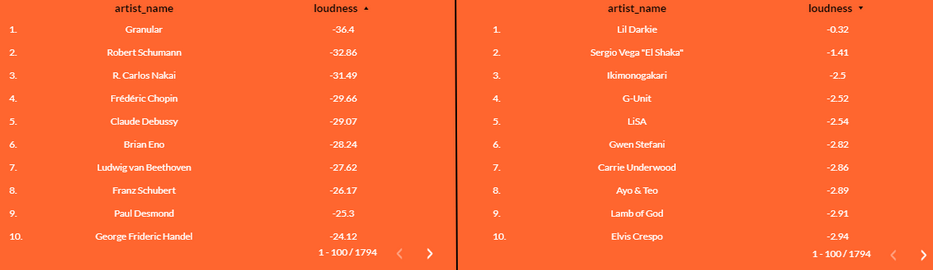
La gran mayoría de artistas con el volumen más bajo (a nuestra izquierda) están dentro del área de la música clásica. Nada sorprendente aquí. Pero si nos movemos al espectro con mayor ‘volumen’ es cuando empezamos a percibir cosas extrañas. Por ejemplo, nos encontramos que Gwen Stefani tiene mayor volumen que Lamb of God, SOAD tiene prácticamente el mismo ‘volumen’ que Rosalía o Calvin Harris. ¡Hasta Sean Paul es más ruidoso que Sex Pistols!
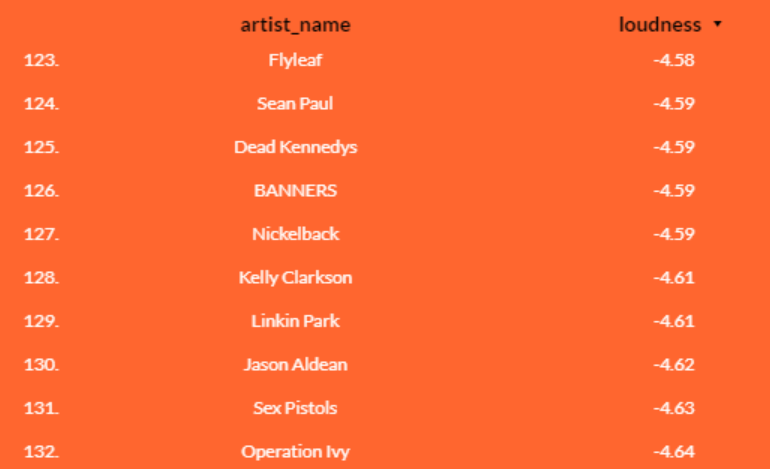
Y con esto concluimos nuestro análisis, ya que poco más se puede añadir. El hecho de que cierta música que no debería ser conceptualmente algo ‘ruidoso’ tenga estos niveles de volumen no hace más que afianzar el hecho de que se ha producido (y sigue, aunque en menor medida) una escalada de elevación sónica de las canciones que se podría comparar con los decibelios alcanzados por las grandes industrias metaleras en la era de la revolución industrial.
Y sino me creéis, sacad los datos y comprobadlo.
