


Web Scraping se llama a la técnica de obtener información de una página web mediante el uso de software o scripts que escribimos nosotros mismos.
Este software lo que suele hacer es analizar la estructura HTML de una página web y extraer la información de aquellas etiquetas que resulten de interés. Por lo que, antes de escribir cualquier script o poner a funcionar cualquier software, es necesario observar primero cómo se organiza el HTML de la página web de la que queremos obtener información.
Pongamos de ejemplo un “scraper” que obtendrá información sobre los precios de smart tv de amazon:
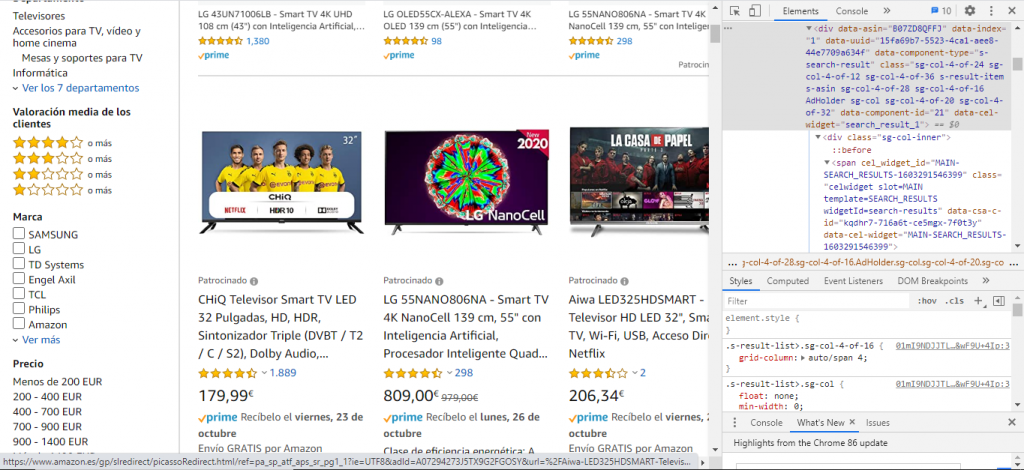
Lo primero en lo que debemos fijarnos es en la url ya que la utilizaremos en nuestro “scraper” para obtener la información que nos interese.
Una vez dentro de la página de ofertas empezamos a analizar la estructura del HTML.
Observamos que todas las ofertas están listadas dentro de un
div con la clase s-main-slot, a su vez cada producto
está dentro de otro div con el atributo data-uuid.
Con esto ya tenemos un buen punto de partida, ya sabemos en qué parte del HTML está el contenido que nos interesa.
En nuestro ejemplo vamos a extraer el nombre, precio y url de cada producto,
por lo que toca analizar donde está la información dentro del
div de cada producto:
- Precio:
spancon la clasea-price-whole -
Nombre:
a(enlace) con el ida-link-normaldentro de un h2 con la clasea-size-mini -
Enlace:
a(enlace) con el ida-link-normaldentro de un h2 con la clasea-size-mini
Como puedes ver, el nombre y el enlace están en la misma
etiqueta. La diferencia es que el nombre se
encuentra dentro de la etiqueta y el enlace lo contiene el
atributo href del enlace.
Bien, ahora que sabemos cómo está estructurado el HTML es hora de empezar a picar un poco de código y realizar un pequeño “scraper” con PHP.
Scraper escrito en PHP
Lo primero que vamos a hacer es iniciar un proyecto utilizando composer, así que abrimos un terminal y escribiremos:
composer init
Para realizar el “scraping” utilizaremos el paquete Goutte que instalaremos mediante composer:
composer require fabpot/goutte
La comodidad de este paquete es que nos permite trabajar con selectores CSS haciendo que filtrar el contenido que queremos sea bastante intuitivo.
Con este pequeño script seremos capaces de hacer “scraping” a la página de ofertas de amazon:
<?php
require_once '../vendor/autoload.php';
use Goutte\Client;
use Symfony\Component\DomCrawler\Crawler;
$client = new Client();
$crawler = $client->request('GET', 'https://www.amazon.es/s?k=televisores+smart+tv&__mk_es_ES=%C3%85M%C3%85%C5%BD%C3%95%C3%91&crid=21Y28T9QMH8LQ&sprefix=televisores%2Caps%2C173&ref=nb_sb_ss_i_1_11');
$crawler = $crawler->filter('div.s-main-slot div[data-uuid]')->each(function (Crawler $node){
try {
$price = $node->filter('span.a-price-whole')->first()->html();
$title = $node->filter('h2.a-size-mini a.a-link-normal')->first()->text();
$url = $node->filter('h2.a-size-mini a.a-link-normal')->first()->attr('href');
echo 'PRODUCT: ' . $title . PHP_EOL;
echo 'PRICE: ' . $price . PHP_EOL;
echo 'URL: ' . $url . PHP_EOL;
echo '...............' . PHP_EOL;
} catch (InvalidArgumentException $e) {
echo 'FAILED GETTING A PRODUCT ' . $e->getMessage() . $e->getMessage();
}
});
Para este ejemplo mostramos la información por el terminal:
PRODUCT: Television LED 50" 4K INFINITON Smart TV-Android TV (TDT2, HDMI, VGA, USB) (50 Pulgadas) PRICE: 289,00 URL: /gp/slredirect/picassoRedirect.html/ref=pa_sp_atf_aps_sr_pg1_1?ie=UTF8&adId=A0702342WW2SPT5PAQCT&url=%2FTelevision-INFINITON-Smart-TV-Android-Pulgadas%2Fdp%2FB07VXQQ5JD%2Fref%3Dsr_1_1_sspa%3F__mk_es_ES%3D%25C3%2585M%25C3%2585%25C5%25BD%25C3%2595%25C3%2591%26crid%3D21Y28T9QMH8LQ%26dchild%3D1%26keywords%3Dtelevisores%2Bsmart%2Btv%26qid%3D1603434010%26sprefix%3Dtelevisores%252Caps%252C173%26sr%3D8-1-spons%26psc%3D1&qualifier=1603434010&id=4114882010574106&widgetName=sp_atf ............... PRODUCT: RCA RS32H2 Android TV (32 Pulgadas HD Smart TV con Google Assistant), Chromecast Incorporado, HDMI+USB, Triple Tuner, 60Hz PRICE: 189,99 URL: /gp/slredirect/picassoRedirect.html/ref=pa_sp_atf_aps_sr_pg1_1?ie=UTF8&adId=A08846331IQPR268E4WHF&url=%2FRCA-Pulgadas-Assistant-Chromecast-Incorporado%2Fdp%2FB082MMBRVP%2Fref%3Dsr_1_2_sspa%3F__mk_es_ES%3D%25C3%2585M%25C3%2585%25C5%25BD%25C3%2595%25C3%2591%26crid%3D21Y28T9QMH8LQ%26dchild%3D1%26keywords%3Dtelevisores%2Bsmart%2Btv%26qid%3D1603434010%26sprefix%3Dtelevisores%252Caps%252C173%26sr%3D8-2-spons%26psc%3D1&qualifier=1603434010&id=4114882010574106&widgetName=sp_atf ............... PRODUCT: CHiQ Televisor Smart TV LED 40 Pulgadas FHD, HDR, WiFi, Bluetooth, Youtube, Netflix, Prime Video, 3 x HDMI, 2 x USB - L40H7N PRICE: 249,99 URL: /gp/slredirect/picassoRedirect.html/ref=pa_sp_atf_aps_sr_pg1_1?ie=UTF8&adId=A0618336VEK5HQU91ZMY&url=%2FCHiQ-L40H7N-Televisi%25C3%25B3n-Bluetooth-Sintonizador%2Fdp%2FB07ZJBRLF1%2Fref%3Dsr_1_3_sspa%3F__mk_es_ES%3D%25C3%2585M%25C3%2585%25C5%25BD%25C3%2595%25C3%2591%26crid%3D21Y28T9QMH8LQ%26dchild%3D1%26keywords%3Dtelevisores%2Bsmart%2Btv%26qid%3D1603434010%26sprefix%3Dtelevisores%252Caps%252C173%26sr%3D8-3-spons%26psc%3D1&qualifier=1603434010&id=4114882010574106&widgetName=sp_atf ...............
Este script en el fondo lo que hace es enviar una petición HTTP al servidor web y este responde con el HTML del cual extraemos la información. Este método resulta eficaz con páginas web que tengan un HTML estático.
Scraper utilizando Puppeteer JS
La cosa puede complicarse con páginas web que utilicen algún método de renderizado utilizando Javascript o que utilicen llamadas Ajax para completar cierta información. En este tipo de “scraping” no se ejecuta el código javascript de las páginas, solo obtenemos su HTML.
Esto podemos verlo en la página de ofertas flash de Amazon. Esta página realiza llamadas Ajax cada cierto tiempo para comprobar el estado de las ofertas y hasta que no se terminan de realizar estas llamadas no se renderiza el contenido. Si desactivamos la ejecución de Javascript en el navegador observamos que la página se muestra sin contenido:
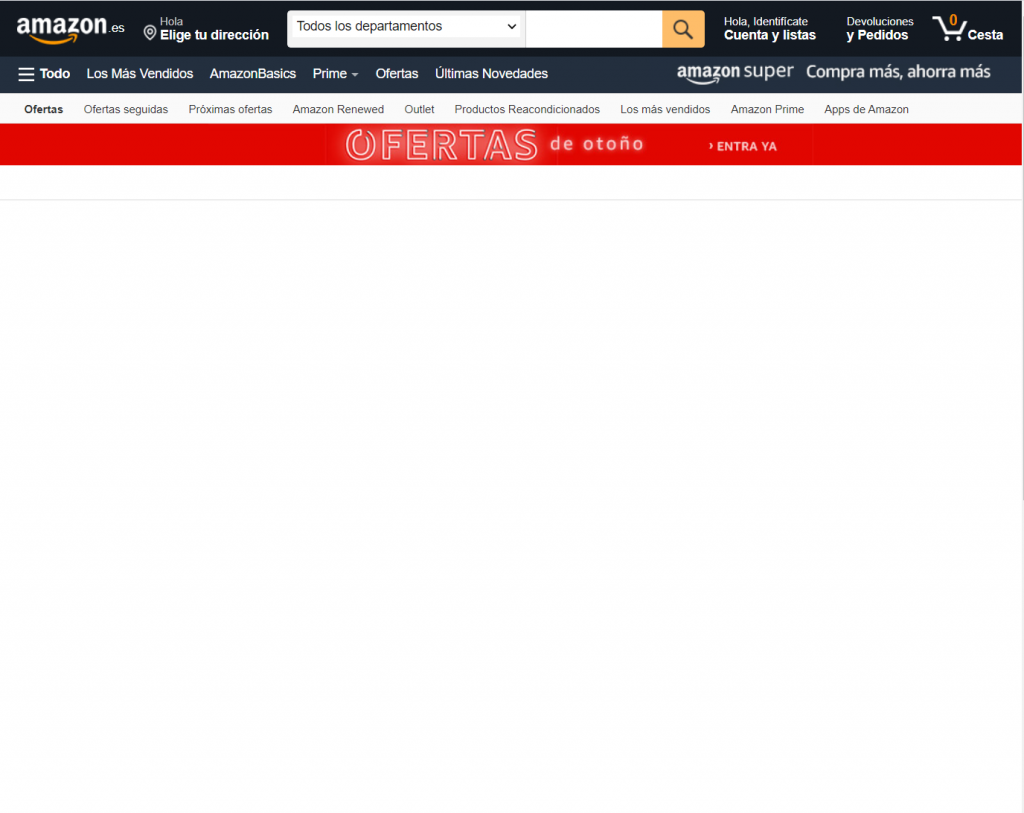
Una manera de solventar este problema es usar el motor de renderizado de un navegador, como si fuese un usuario el que visita la página web. Una de las herramientas más útiles para esto es Puppeteer.
Puppeteer es una librería de Node.js que tiene una amplia gama de usos como capturas de pantalla de un sitio web y generar un pdf con ellas, automatizar test de UI, …
Para hacer todo esto, Puppeteer viene equipado por defecto con una versión de Chromium. Puppeteer crea una instancia de Chromiun con el sitio web que se le especifique y con la que podremos interactuar.
Para empezar nuestro scraper iniciaremos un proyecto utilizando npm, abrimos un terminal y escribimos:
npm init
Ahora instalamos Puppeteer en nuestro proyecto escribiendo en el terminal:
npm install --save puppeteer
Llegó el momento de escribir nuestro “scraper” en javascript:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto('https://www.amazon.es/gp/goldbox/ref=gbpp_itr_s-4_caa3_TDLDS?&gb_f_deals1=dealTypes:LIGHTNING_DEAL&gb_ttl_deals1=Ofertas%2520flash&ie=UTF8')
const result = await page.evaluate(() => {
var data = [];
document.querySelectorAll('div#widgetContent div.singleCell').forEach(product => {
data.push({
"price": product.querySelector('div.priceBlock').innerText,
"name": product.querySelector('a.singleCellTitle').innerText,
"url": product.querySelector('a.singleCellTitle').getAttribute('href')
});
});
return data;
});
console.log(result);
await browser.close()
})()
Y al igual que en nuestro “scraper” escrito en PHP mostramos el resultado por el terminal:
[
{
price: '5,94 € - 8,49 €',
name: 'Pecute Cortauña Perro, Cortauñas de uñas para Perros Gatos Conej...',
url: 'https://www.amazon.es/Cortau%C3%B1as-Profesional-Inoxidable-Medianos-Grandes/dp/B01N9TAYLH/ref=gbps_tit_s-5_4603_538e1f2a?smid=A13EKVTW8DBOVU&pf_rd_p=2aff475b-2ec2-456a-8bbb-e33958304603&pf_rd_s=slot-5&pf_rd_t=701&pf_rd_i=gb_main&pf_rd_m=A1AT7YVPFBWXBL&pf_rd_r=XWNV9E33ZERJQXPH4FYB'
},
{
price: '9,59 €',
name: 'Luz Nocturna Infantil (2 Pack) OMERIL Luz Noche con Luz Sen...',
url: 'https://www.amazon.es/Nocturna-OMERIL-Quitamiedos-Habitaci%C3%B3n-Dormitorio/dp/B07HR89KC6/ref=gbps_tit_s-5_4603_93005d34?smid=A379JFQXZJDMZG&pf_rd_p=2aff475b-2ec2-456a-8bbb-e33958304603&pf_rd_s=slot-5&pf_rd_t=701&pf_rd_i=gb_main&pf_rd_m=A1AT7YVPFBWXBL&pf_rd_r=XWNV9E33ZERJQXPH4FYB'
},
{
price: '14,24 € - 14,99 €',
name: 'TUUHAW Braguita de Talle Alto Algodón para Mujer Pack de 5 Cu...',
url: 'https://www.amazon.es/TUUHAW-Braguita-Algod%C3%B3n-Culotte-Cintura/dp/B07TM271V8/ref=gbps_tit_s-5_4603_8d826976?smid=A3AH2Y3JH6APFA&pf_rd_p=2aff475b-2ec2-456a-8bbb-e33958304603&pf_rd_s=slot-5&pf_rd_t=701&pf_rd_i=gb_main&pf_rd_m=A1AT7YVPFBWXBL&pf_rd_r=XWNV9E33ZERJQXPH4FYB'
}
]
Como podéis observar los ejemplos de código, tanto de “scraper” de PHP como el JavaScript, son muy sencillos. Pero las librerías que se usan en cada ejemplo son mucho más potentes y pueden realizar más funciones de las que se muestran en los ejemplos.
Os invito a visitar las documentaciones Goutte y Puppeteer para que veáis por vosotros mismos todo lo que pueden hacer.
Aspectos a tener en cuenta
En el mejor de los escenarios podremos extraer la información que queramos cuando queramos utilizando nuestros “scrapers”, pero no será lo normal. Hay páginas que pueden usar diversas técnicas para ponerle la cosa difícil a los “scrapers”, tanto a nivel de configuración del servidor que las aloja como sistemas desarrollados dentro de la misma web.
Lo servidores pueden limitar el número de peticiones que se les puede hacer en un determinado periodo de tiempo, incluso cortar el acceso a direcciones IP que le hagan muchas peticiones. Por lo que hay que tener mucho cuidado con la cantidad de peticiones que hacen nuestros scrapers y cuántas veces los ejecutamos.
En el caso de Puppeteer arranca la instancia de Chromium por defecto en modo “headless”, existen ciertas técnicas utilizando Javascript para detectar navegadores en modo “headless”.
Algunos sitios pueden bloquear nuestros “scrapers” mirando el User Agent de la petición HTTP. Tanto con Goutte como con Puppeteer podemos modificar el User Agent.
Un cambio de diseño de la página hará que el “scraper” deje de funcionar.
