


A lo largo de este post vamos a ver cómo crear un traductor inglés – español utilizando redes neuronales. Para ello haremos uso de Trax, la nueva librería de Google basada en su framework de inteligencia artificial Tensorflow.
Quiero recalcar que, intentando contar las cosas de forma sencilla, es muy probable que esté pegando patadas al significado real de las cosas. Quién conozca a fondo esta temática que me perdone ?. Por otro lado, también hay que tener una serie de conceptos básicos para seguirlo y entenderlo realmente. – Iago González, el autor.
¿Qué vamos a ver?
Conceptos básicos
¿Qué es un generador?
Un generador es una
función en Python que actúa como un iterador. Básicamente,
puede generar un resultado pero puedes seguir iterando con esa función, ya que
utiliza en vez de un return un yield.
En este caso vamos a utilizar generadores para proveer datos de nuestro dataset (conjunto de datos) al entrenamiento. Podemos quedarnos con el concepto de que son unas funciones con las que podremos iterar, en este caso, a través de nuestros datos como si fuera un «streaming de datos».
¿Qué es un token? ¿Qué es que sea tipo subword?
En el mundo del NLP, tokenizar significa dividir una palabra en tokens, que son unidades más pequeñas en las que se puede dividir una palabra (en este caso concreto).
Los tipos de tokenización típicos son word,
char y subword.
Ejemplo:
- me gusta bailar -> ‘me’ ‘gusta’ ‘bailar’
- me gusta bailar -> ‘m’ ‘e’ ‘g’ ‘u’ ‘s’ ‘t’ ‘a’ ‘b’ ‘a’ ‘i’ ‘l’ ‘a’ ‘r’
- me gusta bailar -> ‘me’ ‘gust’ ‘a’ ‘bail’ ‘ar’
En NLP se utilizan las tres modalidades, nosotros utilizaremos
subword por varios motivos:
-
Al trabajar a nivel de
subwordno pierdes el significado pero, al mismo tiempo, limitas mucho el vocabulario. Por ejemplo, ‘bail’ sería un token del vocabulario y además tiene significado, pero si los token fueran a nivel palabra podrías tener: bailar, bailo, bailas, bailando, etc - En el lado contrario están los caracteres que harían el vocabulario más pequeño, pero no tienen significado lo que hace muy difícil establecer relaciones entre las palabras.
Otro término mencionado aquí, muy necesario e interesante es el vocabulario, ya que será necesario disponer de un vocabulario de tokens con los más relevantes.
¿Qué es el bucketing?
Los modelos basados en frases, texto, etc (NLP) tienen muchos requerimientos de memoria. Debido a la gran cantidad de datos y variedad de tamaños este método ayuda a aliviar ese problema.
Para entender la técnica de bucketing debemos conocer varios conceptos básicos: Batches, el tipo de dato como es y, en este caso, el padding.
¿Qué es un batch?
Cuando entrenas un modelo le vas pasando datos y tienes dos alternativas: puedes pasarle datos de uno en uno o enviarle conjuntos de datos (batches). Por ejemplo, un batch de 32 sería un conjunto de 32 «datos» de nuestro dataset.
Antes de explicar el bucketing pensemos en cómo son los datos que vamos a utilizar para hacer un traductor:
Entrenar un modelo Deep Learning de traducción sigue el mismo patrón que cualquier otro modelo basado en aprendizaje supervisado. Esto significa que para entrenar este modelo el dataset dispondrá de la pregunta y la solución a la pregunta, en este caso de la frase en inglés y de su traducción al español.
Vamos a utilizar un dataset, de los que tiene el catálogo de TensorFLow, que contiene 21.987.267 pares de frases (en, es).
Ahora pensemos, habrá frases tipo:
- El perro es de color marrón.
- El salario mínimo interprofesional en Bélgica se ha retraído debido al cambio de estrategia en las relaciones internacionales del país.
Por otra lado, el padding se encarga de añadir un token de relleno para que todas las frases tengan el mismo tamaño. Es la forma de que el modelo entrene con datos «homogéneos».
Esto más o menos lo podemos entender así, si mi frase más corta del dataset es:
Hola mi nombre es Iago -> 5 palabras
Y la frase más larga del dataset es:
Mañana llueve mucho pero me da igual porque justo hoy me han regalado un chubasquero que me protege perfectamente de la lluvia y de la humedad -> 26 palabras
En este caso para utilizar la primera frase necesitaremos añadirle 21 tokens de padding, quedando algo así:
Hola mi nombre es Iago
<PAD> <PAD> <PAD> <PAD> <PAD> <PAD>
<PAD> <PAD> <PAD> <PAD> <PAD> <PAD>
<PAD> <PAD> <PAD> <PAD> <PAD> <PAD>
<PAD> <PAD> <PAD>
El bucketing permite crear buckets (cubos) de ciertos tamaños
y clasificar las frases dentro de esos tamaños. De esta forma no tienes que
desperdiciar tanta memoria rellenando con <PAD> cada frase.
Así que si tengo un bucket de 8 tokens la primera frase quedaría así:
Hola mi nombre es Iago <PAD> <PAD> <PAD>

De esta forma el ahorro en memoria es considerable cuando se trabajan con tantos datos.
Algo más a tener en cuenta: otros conceptos
Aunque hay mucha información y cada punto de los comentados da para escribir varios libros, es importante describir este proceso pues nuestras máquinas solo entienden de números, no entienden de palabras o tokens. Por ello, antes de pasar la info a nuestro entrenamiento, deberemos convertir esos tokens en números gracias a nuestro vocabulario.
Así si nuestro vocabulario es: a (1), el (2), coche (3), patata (4), sonrisa (5), ventilador (6), es (7), le (8), palabra_desconocida (9).
La frase: el coche es una patata por que le falla el ventilador
Se transformaría en: 2 3 7 9 4 9 9 8 9 2 6
Y este proceso, aunque más complejo y completo, se hace sobre todas los datos que se utilizan en el entrenamiento y después en la inferencia (el proceso en el que le pides al modelo que prediga la traducción en este caso).
Transformers
Los transformers son un tipo de arquitectura de redes neuronales que se utilizan en modelos basados en el lenguaje (NLP).
Un transformador es, en el caso de un sistema de traducción, algo que transformará una frase escrita en un idioma a otro idioma. Para explicarlo utilizaré este gran post de Jay Alammar.
El lo explica visualmente partiendo de una entrada y una salida (la deseada) y considerando el transformer como una caja negra que iremos desgranando poco a poco. Nosotros vamos a dejarlo en una breve explicación para ponernos cuanto antes con las manos en la masa.
![]()
Si nos metemos dentro de la caja negra lo que veríamos es un componente de encoders y otro de decoders:
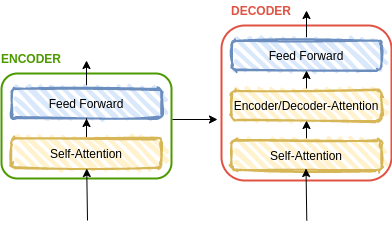
Tanto el componente de encoders como el de decoders es una pila de codificadores y decodificadores (el mismo número en ambos casos):

Los codificadores tienen una estructura siempre igual y los decodificadores también. Los primeros se dividen en dos capas:
- Capa de atención: ayuda al encoder a poner la atención en las palabras que son relevantes. Más información
- Feed forward neural network: arquitectura más sencilla dentro de las redes neuronales.
Los decodificadores se dividen en tres capas:
- Capa de atención
- Encoder/Decoder Antention: ayuda al decodificador a centrarse en las partes más relevantes de la frase.
- Feed forward
A partir de aquí entrarían en juego los tensores que se mandan entre las distintas capas y se puede entrar mucho más en detalle siguiendo el post de Jay Alammar dónde explica la arquitectura perfectamente.
¿Qué es Trax?
Trax es una librería deep learning de «alto nivel» que utiliza como back-end TensorFlow. Lo compararía a Keras.
Vamos a utilizar Trax porque claramente Google está apostando por esta librería, todavía está en su versión 1.3.6 (en el momento de escribir este post) y es una librería fácil de usar y rápida.
Al trabajar con TensorFlow como back end, dispone de grandes ventajas para la puesta en producción de los modelos (donde TensorFLow es el rey de los frameworks de AI para empresas) ya que, entre otras cosas, permite la conversión del modelo en el formato de Keras.
Otra de las ventajas es el poder utilizar el TFDS (TensorFlow DataSets) como veremos en este post.
Para empezar con Trax, no hay que hacer nada más que instalarlo:
pip install –q –U trax
A partir de este punto solo hay que importar la librería para usarla:
import trax
También puedes importar solo lo que necesites:
from trax import layers as tl from trax.fastmath import numpy as fastnp from trax.supervised import training from trax import data from trax import models
*Pro tip:
Instala la dependencia Jax con soporte GPU, por defecto se instala CPU.
Datos
¿De dónde sacamos los datos?
Para entrenar un modelo como este necesitamos datos y, tal como comentamos antes, nos aprovecharemos de las ventajas de TFDS. En concreto nos iremos al apartado de translate donde escogeremos para_crawl que usa la versión 1.2 de ParaCrawl (contiene casi 22 millones de frases en inglés con su correspondencia en español).
Los cogeremos de aquí por comodidad, pero se podría coger la última versión directamente de la web de ParaCrawl que están en la versión 7.1 y que contiene ya casi 79 millones de frases en inglés con su par en español. ¡Ojo! esto se va a descargar unos 6 GB de datos.
# Creamos el generador con los datos para entrenamiento
train_stream_fn = data.TFDS('para_crawl/enes',
keys=('en', 'es'),
eval_holdout_size=0.01, # 1% para validación
train=True)
# Creamos el generador con los datos para validación
eval_stream_fn = trax.data.TFDS('para_crawl/enes',
keys=('en', 'es'),
eval_holdout_size=0.01, # 1% para validación
train=False)
train_stream = train_stream_fn()
eval_stream = eval_stream_fn()
¿Cómo tratamos/transformamos los datos?
Para trabajar con estos datos nos hará falta un vocabulario, en este caso tipo subword, que es como lo ingenieros de Google lo plantean para Inglés/Alemán.
Tendremos que generarlo nosotros e intentaremos sacar un vocabulario de unos 32.000 tokens (aprox). Para ello, lo primero es extraer la información del dataset que bajaremos previamente a un fichero de texto y entremezclaremos las frases en inglés con las frases en español para que coja un vocabulario de los dos idiomas.
i = 0
with open('data/train.txt', 'w') as f:
for text_en, text_es in train_stream:
f.write(str(text_en, 'utf-8') + '\n')
f.write(str(text_es, 'utf-8') + '\n')
if i == 2000000:
sys.exit("Fin")
i += 1
*Pro Tip:
Ponemos un límite de dos millones por dos motivos, el primero es porque hay 22 millones y no necesitamos todo para hacer un vocabulario de 32.000 tokens, el segundo es que el generador es infinito y si no lo paras te estaría volcando datos sin parar.
El siguiente paso es crear el vocabulario utilizando un script que han portado de Tensor2Tensor (lo que era antes Trax) a Trax.
Clonamos el repositorio en local:
git clone https://github.com/google/trax.git
Ejecutamos el comando:
python trax/data/text_encoder_build_subword.py \ --corpus_filepattern=data/train.txt --corpus_max_lines=40000 \ --output_filename=data/paracrawl.subword
*Pro tips:
-
Hay varias variables con las que tienes que jugar para conseguir los
32-35 mil tokens. Uno es el
corpus_max_lines, al que le indicas de ese txt con dos millones de líneas, cuántas vas a usar. También podrías utilizar otromin_countque por defecto es 5 y especifica el mínimo número de veces que tiene que salir el token. -
Si te falla el scrip, asegúrate de pasar el main en
app.run.
Ahora que tenemos el vocabulario, ya se pueden codificar las palabras como números, es decir, tokenizar el dataset:
# Tokenizar el dataset. tokenized_train_stream = data.Tokenize(vocab_file='paracrawl.subword', vocab_dir='data/')(train_stream) tokenized_eval_stream = data.Tokenize(vocab_file='paracrawl.subword', vocab_dir='data/')(eval_stream)
El siguiente paso será definir el EOS (End Of Sentence). En este caso usaremos un 1 y crearemos una función que añada en el pipeline el EOS, y después lo aplicaremos:
# Añadimos EOS a los datos tokenized_train_stream = append_eos(tokenized_train_stream) tokenized_eval_stream = append_eos(tokenized_eval_stream)
También debemos filtrar «las frases» por tamaño (cantidad de tokens), por si a alguien se le ocurre meter El Quijote entero, como si fuera una frase. Vamos a limitar el dataset de entrenamiento en 512 tokens cada frase y el de validación en 1024:
filtered_train_stream = data.FilterByLength(
max_length=512, length_keys=[0, 1])(tokenized_train_stream)
filtered_eval_stream = data.FilterByLength(
max_length=1024, length_keys=[0, 1])(tokenized_eval_stream)
Nota: length_keys se utiliza para indicar sobre
qué keys se aplica este filtrado. Aquí se hace sobre el inglés y el español
(en, es).
Ahora llega el momento de
dividir en batches y en buckets, creando así el generador
organizado (Cada batch_size[i] corresponde con su bucket o
boundaries[i] de esta forma es más eficiente en memoria):
boundaries = [8, 16, 32, 64, 128, 256, 512, 2048]
batch_sizes = [256, 128, 64, 32, 16, 8, 4, 2]
train_batch_stream = data.BucketByLength(
boundaries batch_sizes,
length_keys[0, 1])(filtered_train_stream)
eval_batch_stream = data.BucketByLength(
boundaries batch_sizes,
length_keys[0, 1])(filtered_eval_stream)
Ahora toca añadir el padding a las frases incluyendo el token <PAD> hasta rellenar cada bucket. En este caso, el token es el 0:
train_batch_stream = data.AddLossWeights(id_to_mask=0)(train_batch_stream) eval_batch_stream = data.AddLossWeights(id_to_mask=0)(eval_batch_stream)
Ahora definiremos el modelo Transformer para el que utilizaremos los mismos hiper-parámetros que se utilizaron para entrenar el modelo Inglés-Alemán y que podemos observar en Github, cuando hacen un ejemplo de inferencia.
model = models.Transformer( input_vocab_size=33300, d_model=512, d_ff=2048, dropout=0.1, n_heads=8, n_encoder_layers=6, n_decoder_layers=6, max_len=2048, mode='train')
En input_vocab_size (tamaño del vocabulario) puedes poner el
número de tokens que tienes o menos, pero después deberías usar el mismo para
hacer la predicción. Explicamos estos parámetros:
input_vocab_size– Tamaño del vocabulario-
d_model– Dimensión de varios puntos de la arquitectura, como la salida de la capa de embedding -
d_ff– Tamaño de la capa Dense del FeedForward (tanto en el codificador como en el decodificador) -
dropout– Probabilidad de descartar valores de activación en las redes neuronales dentro de los codificadores/decodificadores n_heads– Número de «attention heads»n_encoder_layers– Número de bloques de codificadores-
n_decoder_layers– Número de bloques de decodificadores -
max_len– Símbolo máximo en el PE (Positional Encoding), Ver paper (punto 3.5) para más información -
mode– Aquí indicamos si es para ‘train‘, ‘eval‘ o ‘predict‘. Para la inferencia utilizaremos ‘predict‘
El siguiente paso será crear la tarea de entrenamiento y la de validación. Aquí puedes jugar con los hiper-parámetros. En mi caso, he utilizado estos:
train_task = training.TrainTask( labeled_data=train_batch_stream, loss_layertl.CrossEntropyLoss(), optimizertrax.optimizers.Adam(0.01), lr_scheduletrax.lr.warmup_and_rsqrt_decay(n_warmup_steps=20000, max_value=0.001), n_steps_per_checkpoint=20000) eval_task = training.EvalTask( labeled_dataeval_batch_stream, metrics[tl.CrossEntropyLoss(), tl.Accuracy()], n_eval_batches=20)
Ahora ejecutamos las tareas en un loop, con un número de pasos que definiremos:
training_loop = training.Loop(model, train_task eval_tasks=[eval_task], output_dir=output_dir) epochs = 500000 training_loop.run(epochs)
Algo que podríamos añadir a este loop es un callback, para finalizar el entrenamiento cuando el modelo no mejore.
Resultados
En este post lo tenéis casi todo para montaros un muy buen modelo de traducción. Dejo a vuestra imaginación y estudio el cómo se hace la inferencia, pero os pego el resultado de una prueba:
- Frase original:
The good news is that puppies sleep a lot, although they do not always sleep through the night, and your pup may wake the household whining and barking to express his displeasure at being left alone
- Frase tokenizada:
[ 40 378 3061 21 30 5024 20386 25 7354 6 1352 2 2932 93 68 65 557 7354 222 5 1136 2 11 59 5024 477 233 11770 5 12232 9829 2239 11 22105 77 13 5344 101 21584 4837 2089 72 332 813 2859 1]
- Predicción:
[ 60 1299 13497 25 15 19 22015 20535 17 33267 30482 9 576 2 1066 41 435 33267 30482 9 239 7 1008 2 10 37 22015 20535 9 124 8093 45 3163 15 17800 9 10 17575 6 24 17921 37 21586 14733 29 45 132 7556 568]
- Traducción «detokenizada»:
La buena noticia es que los cachorros duermen mucho, aunque no siempre duermen durante la noche, y su cachorro puede despertar al hogar que grita y ladra para expresar su disgusto al ser dejado solo
