Hoy en día, el término Big Data es uno de los más utilizados por las organizaciones, por lo que cada vez se apuesta más fuerte por tecnologías que mejoran y optimizan el tratamiento de la información con un elevado volumen de datos en tiempo real. En ese sentido, surgen tecnologías que facilitan este análisis entre las que se encuentran Apache Spark & Kafka.
Las arquitecturas de Apache Hadoop, generalmente incluyen Hadoop Distributed File System, Mapreduce y YARN, funcionan bien para trabajos por lotes o fuera de línea, donde los datos se capturan y procesan periódicamente, pero son inadecuados para el análisis en tiempo real, lo que hace que conviertan a Apache Spark&Kafka como la solución ideal para tratar este tipo de información.
En este artículo hablaremos sobre la arquitectura de Apache Spark y los casos de éxito de empresas que lo utilizan para desarrollar sus plataformas. Encontrarás toda la información sobre la arquitectura de Apache Kafka en el siguiente artículo.

¿Qué es Apache Spark?
Apache Spark es un framework que nos permite el procesamiento de datos distribuidos de manera rápida y eficiente, capaz de orquestar, distribuir y monitorizar aplicaciones leyendo datos de diferentes sistemas de almacenamiento sobre varias máquinas clusterizadas.
A pesar de que Spark lee datos de diferentes soluciones de almacenamiento, no almacena datos en sí mismo si no que está centrado en el procesamiento de manera muy rápida y eficiente, puesto que todo ese procesamiento lo realiza en memoria, lo que impulsa esta tecnología para ser una de las mejores soluciones para el procesamiento de datos en tiempo real (Streaming)
Una de las características más reconocibles de Apache Spark es que es una plataforma que consta de diferentes APIs para trabajar en Python, Java, Scala, SQL y R y módulos que permiten que sea utilizado de manera general:
- Spark Streaming: Spark tiene la posibilidad de gestionar una gran cantidad de datos en tiempo real, a través de un procesamiento continuo.
- Spark SQL: Permite consultar datos estructurados y bases de datos relacionales.
- MLlib: Spark dispone de una librería propia con algoritmos de Machine learning.
- GraphX: Proporciona una API para el procesamiento gráfico.
- Bagel (Pregel on Spark): Modelo simple de procesamiento de gráficos (en desuso, se recomienda el uso de la librería GraphX).
Apache Spark nos permite trabajar con datos más o menos estructurados, integrándose perfectamente con herramientas de Big data como Apache Kafka.
Conceptos y arquitectura básica de Apache Spark
Spark maneja y coordina la ejecución de tareas con datos sobre un clúster de ordenadores. Este clúster de ordenadores es orquestado por un clúster manager, como por ejemplo, Spark Standalone Clúster Manager, Apache YARN o Apache MESOS. Las aplicaciones (Spark Applications) se envían a los clúster managers, que otorgan los recursos necesarios a nuestra aplicación para que podamos completar el trabajo que hemos definido.
Spark Applications
Las aplicaciones que definimos para que Spark pueda interpretarlas se denominan Spark Applications. Básicamente consisten en un driver process y una serie de executor processes. El driver process corre la app principal, se aloja en un nodo del clúster y es responsable de tres cosas:
- Mantener información sobre la Spark Application.
- Responder al programa definido o entrada de datos de un usuario.
- Analizar, distribuir y planificar el trabajo a través de los executor processes.
Los executor processes son responsables de llevar a cabo el trabajo que se le asigna al driver process. Son responsables de dos cosas:
- Ejecutar el código asignado por el driver process.
- Reportar el resultado del cálculo realizado al nodo driver.
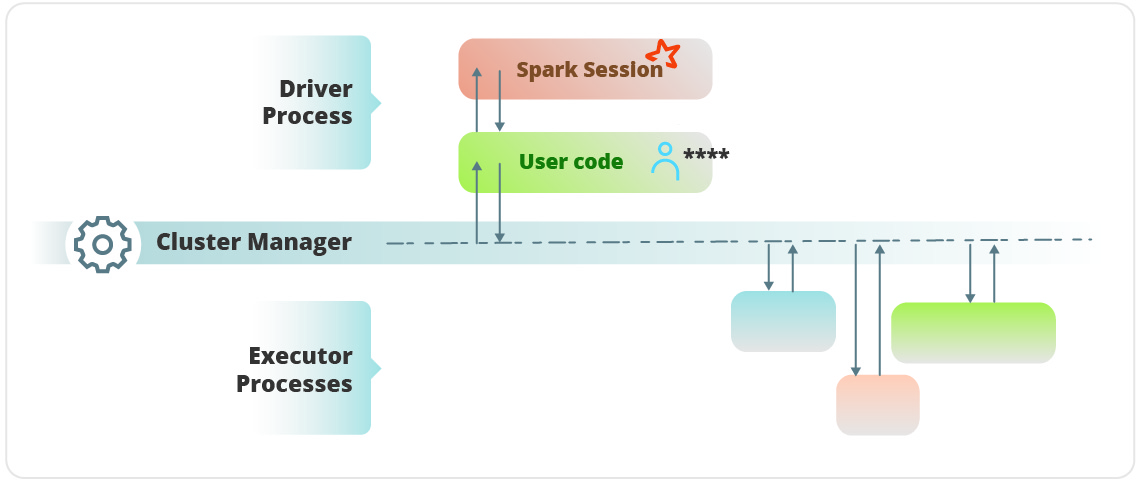
Algunos puntos clave:
- Spark emplea el clúster manager para seguir la pista de los recursos disponibles.
- El driver process es responsable de ejecutar los comandos del driver command para completar una tarea determinada.
- Los executor processes siempre correrán código Spark.
API Spark
Apache Spark cuenta con dos sets de API’s:
- Low – level, sin estructurar.
- High – level, estructurada.
Explicaremos más sobre estos dos tipos más adelante en este artículo.
Spark Session
El control de la Spark Application se hace a través de un driver process llamado Spark Session. La instancia de Spark Session es la forma en la que Spark ejecuta las manipulaciones definidas por el usuario a través del clúster. Existe una correspondencia 1 – 1 entre Spark Session y Spark Application.
DataFrames
Los DataFrames son las API estructuradas (High – level) más comunes. Podemos representarla como una tabla de datos con filas y columnas. La lista que define los tipos de columna se denomina schema. La diferencia entre un DataFrame y una hoja de cálculo es que el DataFrame se aloja en un clúster de servidores, mientras que el documento Excel se aloja en un solo ordenador.
Partitions
Al igual que en Apache Kafka, en Spark también se maneja el término partition. Se usa para permitir que cada executor process pueda realizar trabajos en paralelo. Spark trocea los datos en pequeños sets de datos llamados partitions. El número de partitions determina el número de paralelismo en Spark. Haciendo uso de DataFrames no se manipulan las particiones manual o individualmente, se hacen en conjunto. Las partitions las maneja Spark internamente. Se especifica cómo serán las transformaciones de datos en el clúster y Spark determinará cómo ejecutarlas en el clúster.
Transformations
En Spark, las estructuras core de datos son inmutables, es decir, no pueden modificarse después de que han sido creadas. Para cambiar un DataFrame hay que decirle a Spark cómo te gustaría modificarlo para hacer lo que quieras, pero lo que obtendrás será una copia del DataFrame original con las transformaciones aplicadas.
Hay dos tipos de transformaciones:
- Narrow dependencys: una partition de entrada contribuye a una partition de salida.
- Wide dependencys: También conocidas como Shuffle. Las partitions de entrada contribuyen a muchas partitions de salida.
Con estas transformaciones Spark realizará operaciones llamadas pipelining. Significa que si especificamos múltiples filtros a aplicar en los datos del DataFrame, estos serán realizados en memoria.
Lazy Evaluation
Quiere decir que Spark esperará al último momento para ejecutar el grafo de instrucciones de cómputo.
Actions
Las transformaciones nos permiten construir planes de transformaciones lógicas. Para disparar la computación, ejecutamos acciones. La acción más simple es count, que devuelve el total de elementos de un DataFrame.
Spark UI
Se puede trackear el progreso de un determinado job en el Spark Web UI. Es una interfaz web que levanta Spark, permite revisar el estado de los trabajos enviados al clúster para ser procesados.
Conjunto de herramientas de Spark
Corriendo aplicaciones en entornos de producción
Spark cuenta con varias herramientas para enviar nuestra Spark Application al clúster, Spark-submit es una de ellas. Esta herramienta permite, mediante línea de comandos, enviar el código de la aplicación al clúster y ejecutarla allí. Después de haberla enviado, la aplicación correrá en el clúster mientras esta exista (es decir, complete la tarea) o encuentre un error.
-
DataSets: Type-Safe Structured Apis
DataSets no es lo mismo que DataFrames. DataSet API le da la habilidad a los usuarios de asignar clases escritas en código Java o Scala a los registros dentro de un DataFrame, y manipularlos como si de una colección de objetos tipados se tratase. Para resumirlo, en lugar de asignar tipos básicos a nuestros registros (String, Boolean…), en los DataSets podemos asignar clases como tipos de registro. Esto permite realizar operaciones mucho más mantenibles, facilitando el acceso a los datos que se alojan en ese DataSet.
-
Lower-Level Apis (RDD)
RDD son las siglas de Resilient Distributed Dataset. Las operaciones en DataFrames se construyen por encima de los RDD, y se compilan a bajo nivel para optimizar las operaciones. Los RDD se utilizarán sobre todo para leer o manipular datos en bruto. Otro de sus usos es para paralelizar datos en bruto que están en memoria.
-
Structured Apis – Dataframes, SQL & Datasets
Las Apis estructuradas son herramientas para manipular todos los tipos de datos, desestructurados (logs), semiestructurados (CSV), hasta muy estructurados (Apache Parquet). Existen tres tipos de herramientas:
- DataSets
- DataFrames
- SQL tables & views
En resumen, son la abstracción que se usará para escribir la mayoría de los datos flows.
-
DataFrames & DataSets
Son como tablas con rows y columns bien definidos. Para Spark representan planes de datos inmutables y vagamente evaluados, que especifican qué operaciones aplicar a los datos que residen en alguna ubicación, para generar el resultado deseado.
-
Schemas
Definen las columnas y sus tipos en un DataFrame.
-
DataFrames VS DataSets
La diferencia más clara es que los DataFrames son NO tipados, y los DataSets tienen tipos bien definidos. La mayor parte del tiempo se trabajará con DataFrames. Para Spark, los DataFrames son DataSets de tipo “row”.
DATASETS
Los DataSets son el tipo fundamental de Apis estructuradas. Los DataSets son un tipo de datos muy parecidos a tablas, en las que sus registros son objetos tipados sobre los que poder realizar acciones y mantener el type-safety.
Cuando usar DataSets
Cuando las operaciones que se quiere realizar, no se puede hacer usando una manipulación de los datos del DataFrame, o cuando se requiere o se necesita que los datos sean seguros (type-safety).
-
RDD – Resilient Distributed Datasets
Los RDD se usan cuando el Structured API no es suficiente. Los RDD son apis no estructuradas de bajo nivel en Spark. Hay dos sets de APIS en Spark low – level:
- Uno para manipular directamente el RDD
- Otro para distribuir y manipular ‘distributed shared variables’.
En Spark 2.0 los RDD no son tan necesarios, por norma general es mejor interactuar con Spark mediante API estructurada (DataFrame, DataSet…).
Como funciona Spark en un clúster de servidores
En Apache Spark existen tres modos de ejecución:
- Clúster mode: Es la manera más común de usar Spark. El usuario sube un fichero .JAR precompilado al clúster. El clúster manager lanza el driver process en un nodo worker del clúster.
- Client mode: Lo mismo que el clúster mode pero el driver process permanece en la máquina cliente que envió la aplicación. El cliente es responsable de mantener el driver process, y el clúster mánager de mantener el executor process.
- Local mode: corre toda la aplicación Spark en una única máquina. Logra alcanzar el paralelismo a través de hilos en esa misma máquina.
Conceptos fundamentales de Spark Streaming
Procesar streams es el acto de incorporar, de forma continua, nuevos datos para procesar un resultado. Aquí, los datos de entrada no tienen ningún límite en cuanto a tamaño o espacio, al igual que tampoco tienen un principio o un final. Forman una serie de eventos que llegan al sistema de procesamiento de streams.
Las Spark Applications de usuarios pueden procesar querys sobre el streams de eventos. La aplicación devolverá múltiples versiones del resultado mientras se ejecuta, o actualice un sistema de persistencia de tipo clave – valor.
En ocasiones, el procesamiento de datos en batch se ejecuta junto el stream processing para unir datos de eventos a datos de tipo batch, de forma que se obtiene un resultado de la unión de todo eso.
Casos de uso
- Alertas y notificaciones.
- Reportes en tiempo real.
- ETL (extract, transform, load) incremental.
- Actualización de datos servirlos en tiempo real.
- Generador de decisiones en tiempo real.
- Machine Learning online.
Ventajas de Stream Processing
- Baja latencia.
- Más eficiente que los batch Jobs.
Diseño de aplicaciones en Stream processing
Estas son las maneras de diseñar un sistema de stream processing.
- Record-a-time vs Declarative APIS: pasar un evento a la aplicación y reaccionar a él usando código personalizado. Requiere más mantenimiento, porque hay que mantener el estado manualmente en el tiempo, liberarlo cuando corresponde, etc.
- Event time vs processing time: diferencias entre tiempos, puede ser crucial en ciertos verticales, como IOT.
- Continuous vs Micro-batching execution: en sistemas de procesamiento continuo lo nodos están constantemente escuchando mensajes de otros nodos. El procesamiento continuo ofrece la menor latencia, sin embargo tienen menos rendimiento que la ejecución en micro-batch.
Micro-batch acumula pequeños lotes de datos (500ms) y luego los procesa en paralelo. Tiene menos latencia (+500ms) pero MUCHO más rendimiento.
Spark Streaming API
Existen dos aproximaciones posibles para el Stream Processing en APIS Spark.
- DSTREAM API: es la manera original, basada en diseño en micro-batch.
Limitaciones: se basan totalmente en objetos Java/Python, que es lo contrario al concepto de DataFrames y DataSets. También se basan en processing-time, con lo que para manejar event-time processing hay que hacer implementaciones específicas.
- STRUCTURED STREAMING: permite hacer más y mejores operaciones que DSTREAM. Se basa en un modelo de micro-batch, aunque existe también un modo experimental de continuous processing.
Se ha diseñado para construir end-to-end applictions que combinen streams, batch y querys interactivas.
Es más fácil de usar que los DSTREAMS.
Structured Streaming Basics
Las aplicaciones con Spark Streaming (estucturado) usan las APIS estructuradas de Spark, y esto quiere decir que podemos usar DataFrames, DataSets y consultas SQL sobre los datos. Los usuarios expresan la ejecución en streaming de la misma manera que lo harían con los procesos en micro-batch.
La idea principal del streaming estructurado es tratar el stream como si de una tabla se tratase. El job verifica periódicamente si hay nuevos datos de entrada, los procesa, actualiza algunos estados internos en el state store y actualiza el resultado.
Core concepts
Structured Streaming se ha diseñado para ser simple. Pueden realizarse este tipo de operaciones:
- Transformaciones y acciones
- Orígenes de datos: Kafka, S3, sockets…
- Sinks: es decir, el destino del set resultante.
- Kafka
- Casi cualquier formato de fichero
- Foreach sink
- Console sink (testing)
- Memory Sink (debug)
- Output modes: como queremos que Spark guarde los datos:
- Append
- Update
- Complete
- Triggers: definen cuando los datos son devueltos, es decir, cuando Spark debería buscar por nuevos datos y actualizar el resultado.
- Event-time processing: procesar datos basados en timestamps. Dos posibilidades:
- Event – time
- Watermarks
Casos de éxito. ¿Quiénes utilizan estas tecnologías?
Netflix
Netflix utilizan esta funcionalidad para obtener información inmediata sobre cómo los usuarios interactúan para mostrar recomendaciones de contenido audiovisual en tiempo real.
Uber
Todos los días, esta empresa multinacional de reserva de VTC (vehículo de transporte con conductor) online recopila terabytes de datos de eventos de sus usuarios. Al usar Kafka, Spark Streaming y HDFS, para construir una ETL continua, Uber puede convertir datos de eventos no estructurados sin procesar en datos estructurados a medida que se recopilan, y luego usarlos para análisis adicionales y más complejos.
A través de una ETL similar, Pinterest puede aprovechar Spark Streaming para obtener una visión inmediata de cómo los usuarios de todo el mundo están interactuando con los Pines, en tiempo real. Como resultado, Pinterest puede hacer recomendaciones más relevantes a medida que las personas navegan por el sitio y ven Pines relacionados para ayudarlos a seleccionar recetas, determinar qué productos comprar o planificar viajes a varios destinos.
Descubre también todos los secretos de la arquitectura de Apache Kafka en nuestro próximo artículo.
Artículo en colaboración con nuestro compañero Sergio Sánchez de Ipglobal Tech Hub.
